Your humble blogger is a beached whale as a result of the steady march of police state practices on the Internet. And to calibrate how heinous the underlying situation is, Lambert, who has 20 years of experience as a computer professional, calls my current mess the technology equivalent of being shoved into a minefield without any signs. And as you’ll see below, I’ve already stepped on one mine.*
Like many who consume a lot of information, I depend on an RSS reader to scan a lot of sites and keep on top of news. I was very unhappy when Google killed Google Reader in July 2013. I duly exported my feeds to Digg and Feedly, two of the most promising alternatives. I finally settled on Feedly as the better, at least at that point in time. I later upgraded to Feedly Pro, which meant I paid a fee, so that I could search articles.
I deleted all my cookies from Firefox, the only browser I had used for accessing Feedly, around midnight. Astonishingly, I could no longer log in. The tech experts I conferred with find this outcome to be on the far tail end of bad user outcomes, as in there is no way this should happen and therefore no reason for me to have anticipated it and taken preventive measures.
And the outcome is serious for a big information consumer like me. I have lost my RSS current feed. And I’ve tried the usual password retrieval routes. Nothing came back.
This is a huge loss; it will take me hours when I don’t have hours to reconstruct my RSS reader. And to add insult to injury, Feedly has ripped me off by virtue of my having paid for a year of a plan when I haven’t gotten a year of service.
The underlying evil, and this IS evil, is that Feedly now has only what is called a “social login” meaning you cannot even have an account unless you login via a social media account like Twitter, Facebook, or Google+. Here is how they are innocuously described in Wikipedia:
Social login, also known as social sign-in, is a form of single sign-on using existing login information from a social networking service such as Facebook, Twitter or Google+ to sign into a third party website in lieu of creating a new login account specifically for that website. It is designed to simplify logins for end users as well as provide more and more reliable demographic information to web developers…
Social login links logins to one or more social networking services to a website, typically using either a plug-in or a widget. By selecting the desired social networking service, the user simply uses his or her login for that services to sign on to the web site. This in turn negates the need for the end user to remember login information for multiple electronic commerce and other websites while providing site owners with uniform demographic information as provided by the social networking service. Many sites which offer social login also offer more traditional online registration for those who desire it.
I like the idea of having my information shared across so many vendors (and therefore much easier for the NSA to mine) even less than having my refrigerator be able to talk to my watch.
When I set up my accounts on Feedly and Digg, I did not use a social login. I’ve avoided social media as much as is humanely possible for someone conducting an Internet-based business (I do use Twitter but never for Web identification purposes). For instance, I had despite Google’s urgings, had strenuously avoided upgrading to Google+ until recently. I have taken what modest steps I can to reduce the amount of information I give to the surveillance state (for instance, having only a stupid phone, not having a Facebook account, not using online banking, using wired Internet connections whenever possible).
But it turns out that Feedly now requires social logins (they include Evernote and Microsoft accounts):
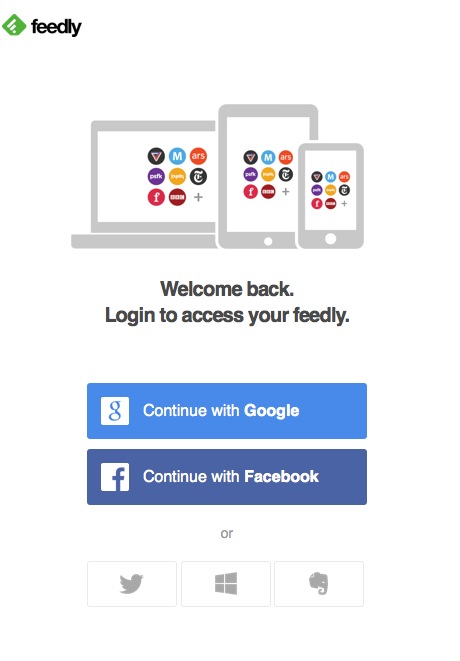
So even though they happily took my money back in their relatively early days, when they also allowed for a mere e-mail address to create an account, now that they’ve gone full Big Brother, my account is no longer retrievable. I somehow peculiarly was able to circumvent later-imposed social login requirement by virtue of still having cookies from when they allowed non social logins. But with their new policy firmly in place, they don’t recognize me as a valid user, despite having paid for their service, and I can’t log in at all, since my account wasn’t set up under any of these routes. As a result of being a social login non-person, I can’t do a password reset either.
And yes, I actually did retain the very long account number Feedly assigned me when I upgraded to their Pro service. That is utterly useless if you can’t reach a human being to get them to sort it out. Predictably, Feedly, like Google, does not allow customers to contact them. They have the usual “go fuck yourself” user “Customer Feedback & Knowledge Base for Feedly.” Working hypothesis: the longer and more faux friendly the name, the less interest they have in actually helping. This is confirmed by the fact that there is no phone number on Feedly’s site, the only phone number listed for them on the Internet is no longer working, and directory information has no current listing for Feedly.
And Digg? Sadly, the result there is an even clearer version of the Feedly drill. I thought I could at least go to Digg as a backup, retrieve my RSS feeds as of the death of Google Reader, and update them. No luck. I can’t get to my Digg RSS feed for precisely the same reason:
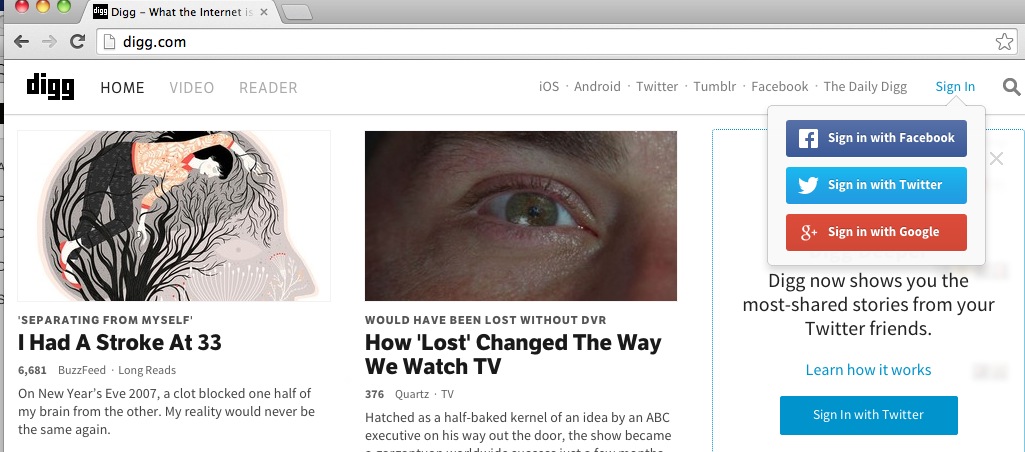
See the upper left? You can log in using only Twitter, Feedbook, or Google+. When I tried logging in using my @nakedcapitalism.com e-mail address, it was an immediate fail. Why?
Again, it’s the changeover to social logins after I created my account. It is (or ate least was) considered to be good protocol NOT to use the same user ID and password combination on different accounts. So my password I set up for my @nakedcapitalism.com account on Digg of course was different than the password I use with Google.
But remember my mention in passing that I had finally relented and gone over to the dark side of Google+? That @nakedcapitalism.com address is a Google mail address and was therefor “upgraded” to Google+. That means my Google+ password is different from the password I had used when I set up the Digg account. So logging in under Google+ (the only way I can log in to Digg) meant it got information from Google that was inconsistent with the password I used when I created the account. Digg, unlike Feedly, at least has the decency to show that it is confused:
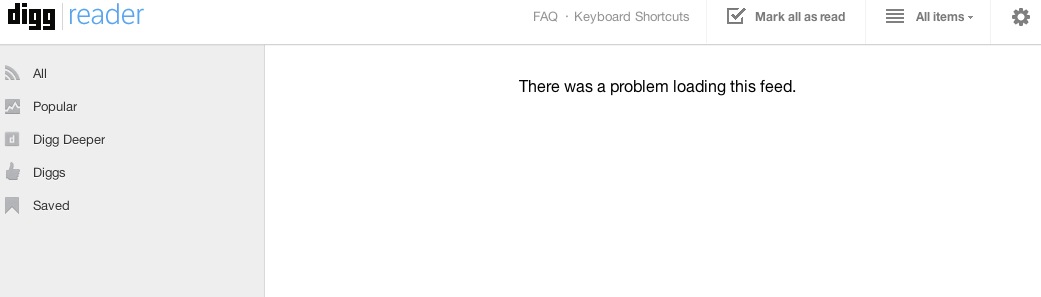
Step back and consider the big picture implications of my tale of woe. The justification for the implementation of social logins was to make it easier for users. That’s clearly bogus. If the concern was the user experience, these site would also allow for customers to use e-mail addresses not connected to social media. Mind you, if the site owners wanted to nudge users in the direction of using social logins, they could make those options far more prominent and make users click through extra screens to get to other options for creating accounts.
Moreover, there was nothing terribly broken about the old system of having a valid e-mail address as your user name. That e-mail address was unique. If you somehow had trouble with the password, you could always get a temporary one sent to that e-mail address for a reset. The only time you might have a problem is if you somehow lost control of an e-mail address (I had that frustratingly happen with an @mac.com account, which I had even paid for for years back in the day when Apple made you pay for their cloud storage. The password stopped working some months ago, and the system perversely rejected valid answers to security questions. Fortunately, that was a tertiary account; I have more control over my other e-mail addresses).
There is no particular reason to regard Google and Facebook accounts as any more secure (presumably, if someone got their hands on your computer or mobile device, a skilled hacker could find your passwords or use the fact that the some sites remembered who you were to get inside the account). Moreover, having so many accounts tethered together increases the personal costs of a security breach.
So let’s not kid ourselves as to what this social login push is really about. The RSS reader case makes the real motivation abundantly clear. It isn’t about collecting better demographic information for the purpose of ad sales. Neither Feedly nor Digg sell ads.
The Digg and Feedly insistence on social logins only looks to be about tracking the identities and habits of heavy users of information. Top on the list of RSS reader customers is journalists. It presumably would not be hard to query “who has these particular anti-party-line sites in their RSS readers and accesses them regularly,” track it back to the actual users, and look at their networks. This approach to mapping interests and networks isn’t just a more convenient way to get at a particular user’s priorities and habits than looking at Facebook likes or sites followed on Twitter; it’s also likely far more accurate, since the interaction with RSS (for heavy users) is far more frequent and thus provides better data.
So if readers can recommend a decent RSS reader that is not hostage to the surveillance state, I’m game. I had tried RSS Owl (which is e-mail based) and found it good in some respects, but as not well suited to a large-ish list of sites as Feedly or Digg (it was easier to search but harder to scan). So I do have a somewhat stale RSS feed in RSS Owl to fall back on in the highly likely event that I can’t get my Feedly account back.
However, RSS Owl also required me to use a a security state login when I set up the account, specifically, a Google account. While RSS Owl does not at this stage require a Google+ account, it is prompting me to install a software upgrade. I’m not doing that since I may be about to have the exact same experience as I did with Digg, that if I upgrade, the upgrade includes the social login requirement, which would mean I lose the RSS feed due to my original password not corresponding to my Google+ password. So that is a long-winded way of saying RSS Owl is probably at best a stopgap.
So welcome to life with the technology Stasi. If you want to participate in the modern world, they are getting better and better at making it virtually impossible to escape their efforts at making sure they know what the real you is doing on the Internet.
____
* Yours truly has a documented track record of being able to find and trigger software failures in record time. And while I do do stupid user stuff occasionally, I’ve repeatedly gone to serious tech types with the anomalies I’ve triggered, which depressingly usually happens in the first half hour of using a new program. The experts are able to replicate the problem. After trying to work around it, they conclude that what I have found is a bona fide bug and not user error. Needless to say, this freakish ability to break software has induced an extreme reluctance to learn new programs.


For what it’s worth, I use newsblur. (newsblur.com) It’s open source, and the premium payments go for server hosting and making sure that I’m the customer and not the product. It can import OMPL files, if you have access to any of your backups.
Also a happy paid user of Newsblur – excellent web and iOS app, and worth supporting.
Also a happy user of Newsblur here. The nice thing about it is that it is a one-click easy export of all of your opml feeds so that if you ever lose access to Newsblur, you can just import those into some other client. As an added benefit, the source code is all up on Github, so if the site ever goes down, someone else could put a clone site up and continue improving it. If you’re really good at running linux servers, you could probably even setup a private instance of Newsblur yourself.
Really, it’s ridiculous to not have a way to login without a social site involved. Even Disqus has a disqus account you can sign up for and not use google/twitter/etc to login.
While your feeds may be lost forever, if you have to return to Digg or Feedly, do what i do, I use a 100% fake, not related to me in any way, Google account (and blank G+ profile) for services like these.
You really don’t think Jason is my real name do you?
I do have more than one Gmail account, but Google also pressures you like crazy to merge accounts. I really don’t use the second one, and even so I have to navigate very carefully to avoid the tripwires to have Google tie them together (and presumably kill one or the other).
The easiest route might be to set up a fake FB account since I have no intention of ever using FB.
I use a firefox plugin called sage. No logins, it’s all stored locally. you can’t lose your feeds with it.
Fake Facebook accounts are also easy to create. Create as many as needed, but it will necessitate more passwords and potential confusion.
I keep my passwords in a little book. Not secure if someone breaks in, of course, though it’s lightly disguised. I’ve learned the hard way not to depend on my memory.
(Afterthought) And I’m not as interesting as Yves, though I’ve done my best to get on as many lists as possible. But she’s truly important, both as an influence and as a nexus. that’s a high compliment.
that’s what I was thinking – set up a FB account that you never use
Get a Firefox plugin called BetterPrivacy. I have discovered that I can delete ALL my cookies. Permanently. I accidentally deleted my bank’s cookie and everything works flawlessly.
I don’t think that having a sacrificial Facebook account will help. The issue is that your newsreader activity will be associated with a particular account regardless of whether you use the account for other purposes or not. You will also discover that it is difficult to avoid using the Facebook account if you have one.
One other business reason you don’t consider in your post is that feedly and digg are transferring the costs of authentication to the larger players. The costs to keep out hackers, identify fraudulent accounts, etc are high. Of course it doesn’t come without a cost, but it’s a rational business move to keep costs down.
I, too, was an early Feedly use, migrating from Google Reader. Early on, I linked my account with Google+ and been very satisfied with being able to login to Feedly seamlessly when using Chrome, which is my preferred browser. I use Android and ChromeOS, and have a Chromebook for each member of my family.
There are companies which mine consumer data and generate profiles for every single household in America. There’s no reason to believe the US Government hasn’t done exactly the same thing. We must be even more vigilant to guard against the rise of fascism in our society and across the globe. The freedom of information available on the Internet is a sword which cuts both ways.
First, im sorry about these troubles your having. im running the same set up as you and over the last 3 months ive had google tell me my email act. is unavailable due to my cache. this is BS b/c i clean and sweep daily and deviate little from my usual usage. when i get this warning i open a new tab for the same gmail act…everything goes fine from there. i too was forced into google+ this year. i get the feeling my warnings won’t last. ive got 7yrs of files merged from previous email accounts…evil is lite.
Again, Sorry for your migraine! and Thanks for opening this thread…i need options to batten down the hatches.
The share of websites requiring social media login to post comments has been growing as well.
That’s a very good point. It does make you wonder whether the comments are being tracked.
The other, very disturbing trend is Facebook and Google making constant, increasingly shrill requests that I provide a mobile phone number link to my accounts. That feels to me like little more than tying off the loose ends for the benefit of the NSA.
I’ve noticed that too with yahoo lately – they keep telling me to update my password and provide a mobile number which I’ve declined to do. So far I’m still able to access my email but I can’t give them a mobile # even if I wanted to – I don’t have one.
Very frustrating – If I were a head in the sand type I’d just ditch the internet access but the MSM isn’t going to give me the info I’m after.
Of COURSE the comments are being tracked. You didn’t really think they were private or anonymous, did you?
Probably even here, despite Yves’ best efforts.
Same here. I’ve noticed for years Google wanted my phone number. Yahoo’s insistence seems more recent. Perhaps post-Myers, since she’s from Google?
Phone number, through text messages, serve as a second vector for authentication. The first is your password. The primary use case is that your password is known by a hacker. While they may know your password they won’t know the code Yahoo sends you via text message. Thus the hacker doesn’t get in.
There are the common ways your password is known. First, the hacker directly acquires your password. Second, they get a list of ids and their respective passwords through another company (e.g. linked in) and your id password combo is on the list. And third, through brute force using the passwords from a previous breach or dictionary attack. of course there are other ways, such as heart bleed and torture.
Is it the right thing to do? I don’t know. But I willingly have my mobile number to the big players and my banks to get that second factor authentication and peace of mind.
Yes and kudos to this site for not doing so.
Hi Yves,
I have been using newsfox for the last years and haven’t been able to find anything better than newsfox – for my use (which is RSS feeds on my PC). Created a dummy account on Feedly, but the user experience on Feedly is worse than what I’m used to with Newsfox.
You mentioned ‘searching’, can’t search across blogs with Newsfox.
Btw, Feedly proposes ‘finance’ and ‘financial’ as blog themes. NC doesn’t appear under ‘finance’, and at ~20th place under ‘financial’ (with 8K users).
Have something custom-built from your tech guys or NC readers?
I suppose undeleting the cookies is no longer an option?
When I am up again, we are going to look into fishing them out of a backup. Tony our new tech guy gave detailed instructions.
Even if that works, I probably do need to get on a new RSS reader. I do not want to be this vulnerable, both to data loss and the social login scam.
Yves, if you’re trying to keep your tracking footprint small the first thing you should do is delete all your cookies every single day. There are addons for firefox that will do it for you automatically or on closing the app. I use a plugin called “Self Destructing Cookies” that deletes cookies as soon as you close out of a website. Its easy to use and there is a button to suspend its operation in cases where it interferes with proper functioning of websites (I have to suspend when I log into disqus to comment because once the login screen goes away the plugin deletes the cookie that has me logged in).
Oh, this is useful. Thanks!
another tip: also use BetterPrivacy with Firefox to wipe out Flash cookies, or some sites will recreate your regular cookies from the Flash cookies even though you wipe them out on browser close.
The NSA tracks people at a much lower level in the internet connection and this can not be encrypted by anyone. Data are broken into packets as they are sent and each packet has your IP address and the destination IP address. This can’t be encrypted, so the only way to hide is to use TOR and even that can be tracked by the NSA. I can explain in more detail if anyone is interested.
This is correct. NSA has been doing it, as far as I know, since 1984 when I taught NSA how to hook up to AT&T’s ten national backbone nodes (PLN-Private Line Network) at the time. To understand it look at your left forearm. That’s the pipe. Your wrist is NSA. Your fingers are the global backbone carriers.
The finger/carriers are doing their version of collection with the FB/Google+/Twitter logins. It is the analogous equivalent of closing the air between your left fingers. They can now connect you via the knuckles or phalanges, depending on granularity desired.
Yves, Witopia has a physical Cloakbox you might be interested in for some protection. Another software deterrent is Do Not Track Me by Abine. These foil the marketing websites somewhat, which is why websites are resorting to the FB/Google+/Twitter logins.
To be accurate, NARUS machines exist just above the wrist– the upper two bracelets–in my analogy above. They were to provide legal deniability (what 2007 whistleblower Klein saw in an AT&T room in San Francisco). NARUS machines were originally owned and installed by an Israeli company, now owned by Boeing.
I can’t even access my credit union if I do that. Nor sites I like to comment on – but maybe I should get over that.
glad to be of some little help to you Yves! :)
and OC, cookies shouldn’t affect any of that. Yes, if you delete your cookies it may forget to fill in the blanks on your logins, but logging in by typing them should always work. And for commenting, like I said, with disqus or livefyre I simply disable the plugin with its handy toolbar button for the duration and its all good.
Ahh, but they did. The CU told me outright I couldn’t have web banking if I disallowed cookies. And I was cut off on at least one site (livefyre, not Disqus) even if I logged in manually.
As I said, I could do without both, but the situation is a little worse than you say. Not that I’m at all tech-savvy, but I sicced my son on both of them. No joy.
Okay, there’s confusion between letting them save cookies on your machine or not, and then deleting those cookies once you’re done with using the site. If you don’t allow cookies many sites won’t work at all. So you allow them, but once you’re done you can delete them, say at the end of the day before you close up for the night or whatever. That way they get to put the cookies on your computer, but then you get to delete them so they can’t be used to track you for long periods of time.
Always use incognito/private mode, it’s simpler
What a mess! I know several people who have set up Fakebook accounts for this very reason. That sounds like the way to go- thinking whatever you paid for the feed is lost at sea.
Then of course FB will claim they have x billion users or something in their promotional hype. Half of them are ghosts accounts noone has used in 5 years but didn’t know how to delete, another quarter are entirely for “social logins” ….
The ‘walled garden’ approach to the Internet is an effort to consolidate revenue into fewer hands. Apple appears to be the pioneer in this realm. Social login nonsense to get access comes off as benign and nothing to worry about. Yea, right.
I saw tiny tiny feeder RSS, but I am not sure on its robustness. http://tt-rss.org/redmine/projects/tt-rss/wiki
I will investigate if this is something to personally tackle in the open source domain.
I disagree that this isn’t about ads. Ads are no longer site specific, they are attached to your identity as you go across the entire internet (and increasingly the “real world”)
As you’ve noted, RSS feeds say very precise information about what a person is interested in, so I imagine the value is considerable and since Digg/Feedly don’t show the ads directly they keep the impression that their hands are clean.
But Feedly and Digg DO NOT RUN ADS so they get no ad revenues. So why from a business standpoint does it benefit them to drive users away by not allowing for non-social logins? There is a cost to them for this choice (I’m not renewing my Feedly Pro account, for instance) and no upside.
You didn’t read my comment closely enough (or it wasn’t clear because what I’m talking about is detailed in the link). They don’t run ads, but they don’t need to because they can just sell the information to ad targeting agencies that collect data from everywhere (including real world transactions) in order to deliver ads on sites that DO use them.
This is the most straightforward way to monetize products where advertising doesn’t fit cleanly into the user interface or user base.
Yep. Straightforward cost-benefit calculation. Increased revenue from requiring social log-in > lost revenue from former users.
They might sell the information they gather to someone who does sell ads; they may be collecting in case they do want to sell ads or to make their company more valuable if they want to sell the company to someone who does sell ads; or they may have plans for some other business model coming soon. Or they may be working with the government or leaving open that possibility for the future. Many possibilities, all bad for us.
I think the most likely use is data capture for future sale of the companies or for later ad sales.
There simply is not much value in this data to data vendors on a stand-alone basis, particularly given how fragmented the RSS market is. But as indicated, it could be valuable to surveillance state types to monitor influencers like journalists in general or in particular.
Don’t you wonder about NSA-driven law or corporate-driven NSA? (TPPA tie-in) At last week’s Moment of Truth town hall in New Zealand, Edward Snowden was talking about how as an NSA analyst he had access to computer identities globally, and could set up “fingerprints” to track targets with, and even the prime minister of a country (or you or me or Yves, I’m thinking) could be a target. Julian Assange talked about how law enforcement was becoming supranational, defeating sovereignty and democracy — that the global surveillance Five Eyes aren’t really controlled or overseen by their respective governments, and the point seems to be to get US law, disconnected from democracy, to apply globally. Kim Dotcom’s lawyer Bob Amsterdam talked about the TransPacific Partnership Agreement and other negotiations in that light, how it coerces other countries into changing their own laws to suit the “US.” Assange said it’s a way of the US effectively annexing other countries. And I’m thinking, nobody asked me, which is why I put “US” in quotes.
(because corporate “moral entrepreurship”)
(“the guy” = New Zealand Prime Minister John Key, who Amsterdam called a traitor to New Zealand for selling NZ out)
Sorry for the long quote, but it all seems like it might apply to what Yves is experiencing, and I hate to rephrase what they know better. Maybe I should have highlighted the phrase “this global war on culture that has been launched by the internet industries of the United States on all of us.” The algorithm needs your data and your identity to own/pwn you you you you you you you you you… it’s what being a master of the universe is all about?
they may not run ads, but I bet their required social media login sites have some sort of financial arrangement with them.
I’ve been using Tiny Tiny RSS: this is essentially open source Feedly that you have to host on your own server.
So, the downside is that you need to purchase your own internet server (e.g. Bahnhof, the Swedish hosts of Wikileaks offer plans for 15 euro/month) and configure it (bare minimum: install webserver, install TTRSS, secure it, configure encrypted backups).
The upside is that this is a pretty affordable and versatile solution (this doesn’t apply to you, but, for instance, there’s a TTRSS android app). Another upside is that you can also use your private internet server for other “de-googlefying” things: host your own encrypted email, website, contacts, calendar, etc.
This does require an investment of time to get going. However there are lots of guides online, so it should be doable with a moderate initial time investment by most people decently comfortable with computers/internet technology.
No tech plumbing for me! This may be a great idea, but didn’t you see that I am the Typhoid Mary of high tech?
If you don’t mind not having details about which posts you have already read synchronised over different devices, I would suggest using a plain desktop RSS client (Firefox, Akregator or many others).
I’ve found the OwnCloud news component (and associated Android app) useful – you can either run your own server or use a free hosted service.
Have a look at PRISM break for more options.
A Q.A. manager told me that most people quickly discover that software is a minefield of unexpected behavior (bugs) and adapt by avoiding any feature that they do not have to use. And when something goes wrong, many people blame themselves for doing something wrong (or daring to go where angels fear to tread).
Software is released with thousands of serious bugs left open in the bug database. Huge swathes of serious bugs are never fixed – they are closed as “Won’t Fix” because, at a tech company, the day you start you are six months behind schedule and the managers who ship new features (instead of fixing bugs) advance to the top echelon. It takes more time for a software developer to fix a bug than it does for someone to think up an excuse for never fixing it: unlikely user scenario, there exists a work-around, a bug that crashes the operating system was in the last release and no one reported it, etc.
RE: RSS reader alternatives
i use feedbin.com
cheap, reliable, and the super nice guy that runs it answers emails w/in 5 minutes.
I like live human support.
That you don’t have to reach via the blog – I saw “Edwin”‘s post below. Note: he owes you money.
You will not find a solution to your problem. This is the logical outcome of capitalism. Capitalists love your strong desire for convenience and they will use it to exploit you. Be inconvenienced and free.
I have not used it and I do not know how it would work for you but neomailbox offers RSS feeds by email:
https://www.neomailbox.com/features/rss-feeds-by-email
They are a privacy focused email provider.
Debian Linux and QuiteRSS is my favorite combination.
https://www.debian.org/
http://quiterss.org/
you should still have a compressed google reader takeout file among your downloads or documents from when you loaded digg and feedly with those feeds you were following with google reader…if i recall, you and others were also testing other readers at the time as well…so at a minimum, you should be able to get back those feeds that you had when google reader quit, either through one of the readers that you rejected at that time, or by using your google reader takeout to set up a new reader on a platform you havent used previously…
i’m still using email sign ins on all the readers i’m maintaining – i’m mostly using feedspot, but also have maintained the old reader, digg, the AOL reader, net vibes and newsblur..
I felt just like you did when iGoogle was shut down. Certainly don’t want to sign up with Facebook just to keep up with my Rss feeds. I have some skill with a CMS called Drupal (kinda like WordPress) and found a plugin for Drupal that let me recreate all my feeds on a website “I” control myself. Don’t need anyone else, or have to trust any site that promises to keep all my info “safe”.
There’s always Mozilla’s Thunderbird.
Excellent suggestion, though I’m unsure that would solve her login troublems.
I use Thunderbird with the Bamboo add-on. Not perfect, but searchable, and will import your opml.xml if you have one. You lose the ability (I think) to synch what you have read across devices. That does not matter to me since I always just use my laptop. I find it somewhat clumsy but I am used to it now and am glad to not have all my feeds/interests known to any 3rd party, no matter how benign they currently may be.
Another pretty-happy Bamboo user here, under Firefox. Not perfect, but the UI has some nice helpful touches, and it usually works well unless some server operator resets the feed.
If surveillance and tracking of your usage habit is a concern then you should not be using any kind of third-party hosted RSS aggregator such as feedly, digg, or the late Google Reader in the first place. Stick with a client-based reader such as FeedDemon or even the built-in RSS reader in Firefox. All you will lose by going that route is synchronization of the feed database and read/unread information across devices.
I use netvibes. They’re good and free. They try very hard to be more than a RSS reader, but you can ignore that. Othereise they’re fast, not ad-driven and let you log in using an email (for now).
I keep up with the Washington Redskins on the Wash Post site and got blocked last week with a warning I’d read my 5 free articles for the month! They said I had to subscribe if I wanted to keep reading. I have no interest in anything WaPo publishes on any topic but the Redskins, so now I access through an iPad and the office computer — tripling the free reads each month. Due to the new math, I won’t anymore read the trivial stuff — like what some player tweeted or recaps of special teams woes. We know they have big problems there so what’s new. This way I get the big stuff — like Tom Boswell or the Mike Wise profile of QB controversy.
Going to another news source–like ESPN or Yahoo Spawts — is out of the question. You get used to certain thoughtstreams.
Maybe the answer is Read Less. It’s hard to know when information becomes data and data becomes noise and noise becomes nonsense and nonsense becomes a hideous sewer down which precious life energy gets flushed. It’s not an easy optimization problem and math won’t help. even though some Geeky freak would probably try. Politics has no boundaries except chaos. and the boundary is wide
I do the same, and also got blocked last week. You can further expand your free reads number by using multiple browsers.
clean your cache. Happens to me on LA Times and that works for me.
Opening an anonymous browser window (in Chrome, for instance) allows you to bypass monthly viewing limit at the NYT. Maybe it works for the WaPo too; try it.
Don’t feed the MSM!
The NYT somehow figured out how to block the anon viewing trapdoor, at least in Firefox. I get the article limit message there now even when I use private browsing.
Just delete those cookies (and “super” cookies and flash cookies) and NY Times won’t be able to track you. I read all the disinformation I want there with no limits! Yay!
How do I delete flash cookies? FF makes it hard to find where to delete cookies at all, and I did wipe them all in the one place I know of to remove them.
Okay, here’s an up to date piece from the EFF on the latest cookie technologies and ways to defeat them: https://www.eff.org/deeplinks/2009/09/new-cookie-technologies-harder-see-and-remove-wide. The eff piece refers to another article but the link is broken so I’m including it here: https://www.isecpartners.com/research/white-papers/cleaning-up-after-cookies.aspx.
The eff piece refers to firefox extensions like BetterPrivacy that can delete flash cookies. But flash cookies aren’t the end of the story, so read the whole thing. Its mostly plain English so it shouldn’t be too confusing.
One thing not mentioned is browser profiling. Your “user-agent” settings that get sent to web servers every time you make a request will detail all sorts of things about what fonts you have installed and many other browser/machine details. It turns out these details wind up being rather unique for each browser so that’s another way they can keep track of you even if you delete all types of cookies regularly. The way to beat this is by forcing your user-agent settings to be very bland and simple so its impossible to track your browser with them. There’s a firefox addon called “User Agent Switcher” that allows you not only to change the user-agent settings but even spoof as a different browser version, type or even computer. This works really well but it can sometimes introduce bugs because some web page code is customized for different browsers so if you report the wrong browser it can make a page not work well. But just changing between different versions of firefox regularly will confuse them nicely ;).
EFF also has their own tool called PrivacyBadger that is pretty cool for avoiding tracking by advertisers like doubleclick, google, etc. The truth is its an ongoing battle that will likely never end but with tools like BetterPrivacy, PrivacyBadger, Self-Destructing Cookies, etc., you can make life a lot harder for these creeps.
I hate the social login trend, and moreover realize that everything I’m doing on the web is tracked. It’s why I use two browsers. One for the login type activities and one for reading and research. I never login to anything on the second browser.
As for the RSS solution, I too use Sage, but I don’t think that it solves your problem. You want to read your feeds and search them and Sage is not really great at that. Here’s Lifehacker’s recommendation and a rich comments section with other suggestions:
http://lifehacker.com/5990881/five-best-google-reader-alternatives
I agree. It’s a serious problem for we, the end-patsies, and a huge externality for the blood-sucking fiends who arrange things so that the surveilance of everything all the time is easier and easier for their aggregating interests. I won’t use Facebook, or Twitter or any other similar thing for this and other reasons.
I hope the back-up route to recovery works for you. I’ve read tech-saavy people say, about computer hard-drives, (or, servers) “Nothing (with rare exceptions) is ever irretrievably lost.”
A friend lost most of a novel manuscript when her computer crashed. Her husband is a programmer and presumably tech-savvy, but the local guy they went to (in a high-tech town) was unable to retrieve it.
Now they use a cloud server for backup – not secure, evidently, but at least remote.
Aiee, the first rule of computing is you MUST backup! External HD or cloud or both.
Here’s how you can have a great RSS feed that doesn’t require a third party reader, using Firefox:
-Create a folder called RSS.
-Save the folder to your Bookmarks Toolbar.
-Subscribe to an RSS feed using Live Bookmarks.
-At the prompt, save the feed to the RSS folder.
This way, you can store all of your RSS bookmarks in one folder that is accessible in a drop-down folder in your toolbar without the need for a third party reader.
PS. If nothing else works and your RSS feed files prove irrecoverable, once you’ve done the painstaking job of re-constituting your reader-lists by hand, save a copy of the data-file (in the needed format) on a thumb-drive—with other similar vital data which, if lost, would create a world of trouble.
I haven’t seen it mentioned yet so I’ll post it.
FeedHQ. Open source at $12.00/year. No ads. A Google search will find it.
I used TinytinyRSS but after a year or so I got tired of maintaining it, plus no offsite feed reading unless I wanted to run a web server.
You can use web interface or a local feed manager. I’m on a Mac so one would be Vienna, but most any will do.
After Google reader went dead I ditched web-based readers and moved to Vienna, an app that doesn’t require any sort of information from the user.
After Google Reader, I went for a desktop app NetNewsWire (Vienna is open source and ok).
Once a month I export my subscriptions as a backup.
I don’t use anything Google anymore. When they started letting everyone use their Google logon for everything then GMail started getting hacked and they wanted all to double and triple verification. They have more dollars than sense.
Good luck on your mission Miss Phelps!
I’m considering dropping Google myself. I’ve been slowly diversifying off of it, but it’s hard finding alternatives that are as good as things like Gmail. I have hope for Mailpile, but it’s not completely there yet. Zoho is really close to being as good as well, but I’m hoping they get that last little bit improved.
For at least five years I’ve been using an extension to Firefox called RSS Ticker. It displays the headlines of unread feeds in a line that scrolls from right to left on either bottom or top (your choice) of the active window and tab. If you mouse-over the headline a small window pops up with a sub-headline, and if you left-click on it the full page displays on the current tab. A right click pops up a context menu with ten choices including opening, marking and copying options. No log in is required; once you install the extension and subscribing to feeds they’ll start scrolling. The only downside is that the app was built by one guy and he, as of 2-3 years ago, no longer has the time available to support it. When he made the announcement he reverted the app to previous version that was more stable, and in the process eliminated the capability to remove feeds from the queue via the context menu. This isn’t a problem, however, since you can delete them by clicking on Bookmarks/Show All Bookmarks and when the library comes up delete the folder that was established when you subscribed to the site.
If you decide to go this route I have one suggestion. The default location for the RSS feed folders is directly on the Bookmarks Tool Bar. I suggest you create a sub folder called something like RSS Feeds and put them in there to avoid unnecessarily cluttering up that toolbar.
I should have mentioned that there is NO log in required.
Yves,
I strongly second Chris’s recommendation:
“If you don’t mind not having details about which posts you have already read synchronised over different devices, I would suggest using a plain desktop RSS client (Firefox, Akregator or many others).”
Seriously consider doing this. As much as is humanly possible, avoid the cloud. That tremendously reduces your profile that can be massively aggregated and spied upon by government and private entities.
I also second the folks who note that these ‘social login’ practices are not about ads, but about your personal data aggregation.
Finally, try to keep to a minimum your acceptance of cookies and use of Javascript in your browsing, though this requires effort on your part, generally in the form of using two browsers.
—–
And finally, finally, while this is about the protection of your readers, not about you, move your site to https by default. By not doing so, you expose your readers to spying on their reading habits on your site. This is technically trivial to do, (it just involves flipping a toggle on WordPress), and costs a very trivial amount to purchase a SSL certificate, (around $10/yr), though some hosting companies force you to pay a hefty markup on this trivial price. This is important.
All news sites should be doing this, but it’s been a tremendously slow slog to get them to go along. Follow the ACLU’s chief tech person @csoghoian for the reasons why, as he’s made it his personal crusade, for very good reason. (One of the few good things about Twitter is that they’ve gone https by default, so governments can’t spy on what you read on Twitter without a warrant or NSL.)
SSL isn’t as trivial as that. SSL burns a fair amount of CPU time too, and in a complex architecture (which is what WP becomes very quickly in high-volume production) it may not be as simple as buying a cert ($10?! Where’s this?) and flipping WordPress’ switch. I think they have to talk to CloudFlare if they want https service.
The Bamboo RSS reader add-on for Mozilla Thunderbird is pretty good, and is searchable. If you can recover your OPML file from Feedly or Digg, it might be a good way to go.
I wanted to join a new online group, women.com and I can’t because they have to verify gender and their way to do this is via Facebook, Linkedin, or Twitter, which I don’t do. I explained that I have a business listing on yelp.com with a video starring me promoting my business, obviously a female. That was Sept. 9, haven’t heard back.
What kind of way is that to verify gender? You should be sending in DNA so they can verify at a chrmosomal level! /sarc
where is your 23andme login?
Using LinkedIn to verify gender is pretty funny because you tell LinkedIn what your gender is when you set up the account.
McMike’s rules of technology:
– The introduction of additional technology never reduces overall complexity.
– Eventually the unanticipated adverse consequences of a new technology become greater than the problems the technology initially solved.
– Any technology that can be used to harm people will be used to harm people.
– New technologies create new categories of problems.
– The easier a technology seems, the less control you have over it.
– The perfect technology will always lie beyond the vanishing point
– You will eventually pay a steep cost for free services
– For every period of time you spend satisfied with a product, you will spend 2x dissatisfied and trapped
– In software vendors’ thinking, the user is the virus
– If it is broke, they won’t fix it
– If it ain’t broke, they will fix it
– Software vendor psychopathy index = number of known unfixed bugs x number of times vendor eliminates perfectly good functions / ease of contacting customer service
Each iteration of tech in the current crapification regime becomes a better mousetrap, harder and harder to opt out of, better and better and keeping you chained to the reservation, better and better at extracting a pound of flesh.
This google dominance will not end well for users. I avoid it and FB like the plague, and so the list of services with social login I boycott increases as well.
Have no fear. The internet thinks censorship is damage and routes around it. You will find a solution and it will be better.
BTW if you must use a social login use Twitter. They collect the least amount of info at registration.
will you bring consider bringing back the full RSS feeds now?
Ugh… Horrible. The one take away from this, time to create an offline back up for my feeds!
Wish I could offer some meaningful advice :(
I can only imagine what a painful time waste this caused for you…definitely unacceptable. Feedly clearly botched the change management and I agree with your comments on the lack of support.
However, I have to disagree with your comment about “nothing terribly broken about the old system”. The average web user has dozens of user/password combinations scattered all over and most users use exactly the same or very similar logins across their shopping sites, feedly, their email and their bank. When feedly inevitably gets hacked, it’s now not just the NSA, but also the Chinese, the Russians and probably a whole bunch of Romanians who have all your logins. Many of the comments above suggest the solution is creating fake accounts which only goes to show just how badly broken the user/password system is. The social login, while arguably sticks the big brother issue in your face, is actually more secure as we are no longer trusting feedly to keep our passwords safe (which is surprisingly tricky) and you can protect your Google or other login with two-factors authentication and know that they have the smartest security guys on staff thinking this through. From a security perspective, it’s a win, and your feedly pro fees can go to more productive uses than keeping extra security guys, lawyers, and damage control guys on constant alert.
On the big brother front, feedly is already likely using google analytics or other “social” links even without the login component so google was already being informed of each and every one of your visits to their site anyway. The social logins are significantly more secure and no worse from a tracking perspective (and arguably more transparent) than the old system of insecure logins and “hidden” trackers.
While the idea of making it easy for the NSA stinks, and thinking about it while I surf makes me fell a bit clausto, at this point, I pretty much assume they already can and do track every single thing I do, and can put it together any way they want whenever they want.
Powerful computers are already assembling huge linked databases of modeled potential activity networks for every single person, with all the various potential items linked to you ranked by strength of likelihood. That’s all automated.
Once you come on an actual person’s radar to be analyzed, at that point whether or not you logged your RSS feed via FB or via some anonymous email account won’t matter a whit. All paths are merely different rat mazes in the same box. And the NSA sees the entire box. It will take the analyst and his program a couple keystrokes to make the link that you spent hours trying to obscure.
So, I stay off Goggle and FB not to foil the NSA, but merely to opt out of the corporate crapification, in a small and solely symbolic way.
If it comes down to the fascists deciding who to round up, I assume that something I said or thought or bought somewhere along the line has already sealed my fate.
If you’ve graduated up their rankings to requiring human analysis, your goose is already cooked.
I would be curious about what measures journalists can take these days to obscure what they are working on and who they talk to. But I would assume that it is effectively impossible. In an era where your usb cable can spy on you, with facial recognition, rfid chips in your wallet, car gps, and license plate scanners, there is no hiding anymore. They already track you all the time, all they have to do is call up the report.
The Liberty Tree has a CCTV camera.
I would recommend inoreader, reminds me of google reader. It also has a large and growing user base plus POWERFUL search features.
InoReader is the only RSS that is worthy of succeeding Google. No social login that I am aware of.
I have been using Inoreader successfully since Google Reader was discontinued. I don’t recall needing a social account and its free, bare-bones design, no ads.
In Firefox:
Create RSS folder.
Store the folder in the Bookmarks Toolbar.
When you subscribe to an RSS Live Bookmark, tore it in the RSS folder.
You now have a drop down menu of all your RSS feeds in your Firefox toolbar, accessible without a third party reader.
Nightmare.
I’ll go back to snail mail before I surrender to social media. Blech.
Yves, the solution to “Social Login” is to make a fake account on facebook for that purpose.
You just need a fresh email account for it. A gmail account should work for that.
But Yves stated intent is to make her activities and preferences less easy to track by the NSA.
A second FB account accessed from the same computer does not achieve that. And would give her a false sense of security as well.
I believe that the mere existence of an RSS list that looks a lot like the list she used before – no matter who logs in – would be recognized by the NSA computers as a likely match almost immediately, and ranked highly as a possible network.
I imagine an NSA analyst calling up a screen so to speak. At the top of the list is Yves known items, like a cell phone and utility bills. Right below that is her Google accounts, and a list of every IP she’s accessed them from. Below that is her “anonymous” FB account, noting it’s nearly identical activity profile, and given a ranking index (i.e. “94% likely to be same person”).
fake FB account created with fake email address…. yes, that’s a work around. But the work around still feeds the social media behemoth by giving FB a new user and thus increases the positive stats for FB’s company, stock price, etc.
Christian made a comment above that is so spot on, Capitalists love your strong desire for convenience and they will use it to exploit you.
Understatement of the day! Another way of putting that regarding the net is, “The noose is tightening.”
Lambert found the following article in Water Cooler of 9/19, Judge OKs serving legal papers via Facebook
As Ambrit said in a sub-comment to that comment thread, this represents a sea change, and it fits in well, though in a very troubling way, with the general trend Yves is talking about here.
The rich irony is that the convenience is a lie.
I spend so much g*dd*nged time mucking with this junk, trying to use it, relearn it when they change it, recover it when it crashes, make sure I have my settings right, waiting for it to load when it is slow, that if I ever tracked my time I would be horrified to see the full scope of the truth.
I am curious though. We all know people who seem to love their tech, can’t get enough of it, swear it makes their lives better, never have a complaint….
I am much more like Yves. Give me as little as possible, because the more I use, the more it breaks.
Is there a fundamental psychological difference? Some kind of need for control? Desire not to be told what to do? Resistance to limitations imposed by unseen unreachable programmers? Hatred of arbitrary remote people who control our destiny? Glass half empty/full dichotomy?
Same thing goes with flying. I know lots of people who still love it and never complain. wtf planet are they living on?
What’s actually happening is the “optional” is being taken out of he equation bit by bit, paid for by all who subscribe to these services as well as by those who use their computers and smart phones and so on for work or whatever combination. Everyone who is “connected”. The point is, I suspect Facebook accounts and the like will become either mandatory in the future or so difficult avoid as to be effectively mandatory. And they will have legal status most of us are simply unaware of now. And Facebook and other social media accounts are really just a stepping stone along the way. The permutations of this are immense and skewed, of course, toward an excruciating degree of electronic control by both elite financial interests and by whatever is left of government.
This would be impossible to implement without stealth, that is without the willing but blind participation of the citizens and so far such participation is overwhelming. The pied piper has a gigantic following that is in itself paying for AND legitimizing the piper’s nefarious ends as the process unfolds.
Exactly, i.e. the legislated mandatory use of debit cards to receive government benefits. They turned a way for getting benefits to people in need into a way for the banks to fleece them of a cut first, and also force them into the credit card spending economy (no cash).
Or filing your taxes online via a paid service.
Or. it’s like trying to claim that driving is a “privilege.”
Already I have clients trying to get me to communicate with them solely via FB. No thanks.
And driving requires a fingerprint now in this state, I don’t think it used to. But “driving is a priviledge”, no matter HOW unfunded public transport, bike lanes or anything else is “driving is a priviledge”
As the database expands geometrically false positives will proliferate. IMO this is a huge invasion of privacy.
http://www.nature.com/news/2010/100317/full/464344a.html
Even the piper thinks he is doing everyone a favor…, or does he?
The convenience isn’t a lie, so much as the hassle is the calculated sales pitch. That used to describe the dismal state of Macintosh freeware. Now it’s the whole market.
I wrote my own RSS reader, thank god. Optimized for quick scanning, I just grab a few thousand headlines and the links from about 440 sites worldwide: MSM news, Alt news, blogs, government agency feeds, Google & Bing news feeds on specific topics (Google has since dropped the ability to create a feed in this way, but the old ones still work fine and Bing still lets a user do so), etc.. I put them in a dozen or so LIGHTWEIGHT web pages optimized to reduce eyestrain on my screens and, presto! I’ve got more news than I really need.
I screen out the ads & cull any material more than 24 hours old, when possible. Many feeds do not contain a pubDate timestamp on their content, but this isn’t really a problem. You can easily recognize content you’ve seen before as you quickly scan down the list of ledes.
Written in PHP, it doesn’t play especially well with Windows scheduling, but that works just fine on a Linux box if you’ve got one of those. I used to and refreshed it in a cron job, on the hour, 24/7. These days, it takes about 10 minutes to complete, but I now just double click an icon on my desktop to run it. First thing I do everyday – like stepping out the stoop to pick up the morning newspaper, but without having to worry about the weather.
I also used to host it on an old PC hanging around here, but I let the domain expire, however, the PHP (5) code I made available on Sourceforge, so if anyone wants to use or play with it, by all means have at it:
https://sourceforge.net/projects/newscrawl/?source=typ_redirect
If you decide to have a go with it, just a mild warning. It’s a greedy algorithm, structured to solve one problem in the way that I wanted it solved, and I didn’t bother writing in any error checking protocols, but it runs perfectly well as long as 2 conditions apply: your connection is up and the other 440 connections are up as well. It’ll hang if the feed connection is down. Having my local connection up hasn’t been a problem, though it has happened – the script races. If I found a feed connection to be unreliable, I simply dropped that feed from the reader. Adding or deleting a feed involves working on a single line of code and I do it all the time.
Nothing like home cooking, people. :)
One of my greatest disappointments and earliest sense of foreboding was when the industry made a formal move in the direction of obscuring what goes on under the covers. In the 80’s and early 90’s Microsoft maintained a remarkably open platform and much the same could be said for Unix (and all it’s flavors) but the price of entry was generally prohibitive unless you were at a university or company. For a brief period, it looked like the big effort was going to be to make the general public more technologically savvy. Everyone was going to write programs (even if highly simplified by graphical representation and tools). Everyone would have at least some knowledge of what was going on under the covers. Then Windows 95 came out and it was immediately clear the trend was going to be in the opposite direction. Hide the file system as much as possible, Make it brainless. Then the explosion of accessibility to the internet that came about due to relatively cheap computers and the ease of using the web interface and the power of http helped cement the bargain with the devil (though the technology itself was neutral) for even though it took almost a decade, again the direction was away from technical know how, and towards convenience. When you think about it, a decade to tame the digital West to pure corporate interests is pretty short.
Yves is actually a very sophisticated user and gets herself into difficulties because of that usage level far more than due to any magnetic quality for problems she might have. Running a blog and trying to avoid intrusion are highly conflicting interests and make issues simply unavoidable.
Most people haven’t a clue to what it is they are giving away when they sign up for a Facebook account or when the use the cloud or even when they open a Gmail account. They hear noises about intrusion, or not, but could care less. The sense of threat or danger is simply not there. So they can easily get along with all the services to keep your computer limping along and they assume that whatever problems they encounter are like rain and sunshine; just part of the weather.
Note also that Unix really had the model (if it weren’t for the proprietary “flavor” wars) Small programs that could be used with each other (the output of one being the input to another) to accomplish amazing numbers of tasks on top of a platform that has still not been matched by Windows. The emphasis being away from gargantuan and rewarding those that were willing to learn even a little bit.
All of which is true, and which is why open source tools seem to be gaining popularity. (thanks to Apache).
I’m old enough to remember the Net before the Web, and if you wanted access, you had to learn a little of what went on beneath the hood. The world of BBS’s. The Net was a courteous place to be in those days, and honestly, browsers didn’t add all that much value. Character cell menus interfaces worked perfectly well. I think they were actually easier to use than pointing devices.
Free enterprise is the Borg: You Will Be Monetized.
I still think the easiest solution for Yves is to stop using net interfaces entirely and switch to the reader provided with her email client. Outlook, Thunderbird, Eudora, whatever. Avoid the entire login process altogether (correct, Yves, logging in is not a requisite for accessing RSS feeds, so why bother with Feedly or Digg? Honestly. They add value? Really?)
It was okay for what it was and what it purported to do: process patents and play Space War. “Small, sharp tools” was a very strong universal design principle that I’m glad won out. “Everything is a file”, not so much. If only folders on disk had been live array objects filled with live file objects, instead of projections of block streams, the world would be a more interesting place…
I seem to remember something recently about how tools were giving way to devices, things like how rapping a wall and listening gave way to the stud finder, the general-purpose computer giving way to the Internet terminal… “it is always possible to add another level of rent-seeking.”
Yves,
This is Edwin from feedly.
Sorry for the frustration. We are going to try to learn from this and get better.
1/ Let me start with the login. We have been leveraging Google login since our inception. This allowed us to make the integration and migration from Google Reader easier. If you have multiple Google account, here is a document to make sure that you login with the right one: http://blog.feedly.com/2014/02/17/login-support-for-multiple-google-accounts/ The only change here is that over time, people asked use for more options so we added Facebook, Twitter, Windows and Evernote.
2/ Let me continue with privacy. What you read is your private garden. We do NOT share this information with anyone. We do not SELL this information to anyone. The fact that you login with Google does not mean that we share your reading information with Google. We do NOT share ANYTHING with Google or anyone else. The login behind OAuth login is to reduce the friction of people login into their feedly.
3/ Regarding support, it is indeed unacceptable that Pro users are not able to access the Pro support page without being logged in. I am going to discuss this with the team and see what we can do to improve this. Between now and then, you can just email me at edwin@feedly.com if you have any other issues.
I apologize for the frustration you had to go through. We are going to learn from this and improve the experience so that other people do not have to go through the same pain.
-Edwin
feedly co-founder and CEO
edwin@feedly.com
RE: “3/ Regarding support, it is indeed unacceptable that Pro users are not able to access the Pro support page without being logged in.”
This would be funny if it weren’t for the immense difficulties Yves now has to confront.
You’ve been in operation since 2008–that is, under your present name–and this “item No. 3” is just occurring to you? Wait! Correction: It didn’t occur to you–no, you apparently had to wait for Yves’ case to occur before it came via a huge glitch before thinking about it. Palo Alto start-up whiz-kids! God help us! This is a prime example of why I despise the cutting-edge stuff over which most people so slobber.
Please, spare me. I know, I know, “These sort of problems can and do occur in every such business.” Yep. That’s part of the problem. Really, someone ought to have thought of: “Hey, how do people who can’t log-in access our help services which, themselves, presuppose the capacity to first login to access them?”
@proximity1
when people sign up for feedly pro, they receive an email welcoming them to the program. In that email, we explain that they can simply reply to that email to access the premium support.
We also have a free support community with more than 14,000 members: https://plus.google.com/communities/113648582731838175643
We also respond to the majority of people sending us tweets at @feedly
Finally, we monitor blogs (it took us about 6 hours to respond to this blog post).
So can we do better for people who have trouble logging in. Yes. But this does not mean that we are not engaged with our community and trying to already serve them the best way we can.
-Edwin
I get nearly 1000 e-mails a day. I cannot retain message like that. My inbox is enormous and I have to weed it regularly to keep it from exceeding permitted size limits
I retained the account number you sent, which for every other tech service I’ve used it more than adequate, but per above proves useless. If I were a mere mortal and didn’t have a blog, I’d be stuck.
I will contact you later today.
So Yves is not mere mortal.
I thought so.
That’s cute. :)
A blog persona is not a mere mortal!
It has its own virtual life!
Thanks for answering! But:
1) Is Yves’s problem — and it was and is almost impossible for me to imagine that deleting cookies would lock a user out of an account for which they had paid — fixed yet?
2) Will the larger problem of forcing users to log in through one of the large social media monopolies be addressed? Specifically, will you now enable users to log in via email accounts, as so many other services do?
Lambert,
1) Yves is not locked out of his account. He initially logged in to feedly using his Google account (that is the only login we supported at inception). He can continue to login to feedly using his Google account. Nothing has changed on that front. I think that Yves just forgot that he initially logged in to feedly using his Google account.
2) We initially supported Google. Based on popular demand we added facebook, twitter, evernote and microsoft. If there is demand for more options, we will definitely consider adding more.
-Edwin
Yves is a woman!
I do set out to confuse people at the outset…
THAT’s what I was was gioing to say: This very, very public slam is probably (as intended) much the most effective, and ONLY, way to actually reach Feedly.
And a message for “Edwin”: too f’ing late. Too bad. Not feeling sorry for you.
Oh, and: thanks for the laugh. I hope you enjoy your conversation with Yves.
I don’t know if Prismatic exactly qualifies as rss/newsreader but it seems like fun to use as an aggregator… not sure about their present login procedure since I signed up a while ago, but I just need an email address. More in the Wikipedia article. Agree that fake accounts are the best approach to all the contemporary BS… for as long as that works.
Seriously, Yves, if your concern is less about your inconvenience here, and more about personal privacy from governmental and private aggregators, move your blog to https default with all due alacrity.
It’s technically simple. It’s reasonably cheap. And it will protect your readers and commenters from trivially simple tracking and aggregation by both governmental and private snoopers.
I put lots of info about me on the Web by publishing this blog. We’ve looked into the https: issue and the only reason to do that is to please Google. It’s not going to do bupkis for my security. And it won’t do much for readers either. As a WaPo article on how to protect yourself from the NSA concludes:
So it’s fairly easy to protect the contents of your communications from government spying. But there’s no easy technological fix to prevent the government from finding out who you’re communicating with.
http://www.washingtonpost.com/blogs/wonkblog/wp/2013/06/10/five-ways-to-stop-the-nsa-from-spying-on-you/
Since the content of the blog and its comments are public, the https: wrapper does NOT protect the contents. And I’d argue it could do readers a disservice, since they’d have the illusion of security. Even using Tor, which was a standard recommendation a few months ago, isn’t looking so safe:
http://www.scmagazineuk.com/microsoft-expert-tor-security-compromised-by-nsa/article/347287/
http://thehackernews.com/2013/09/NSA-can-crack-TOR-Encryptio-Snowden-files-.html
The security issue ease of the surveillance state putting the pieces of your life together. I’d have to go to extreme lengths, as Snowden has warned, to be secure. The officialdom can still do it if they are motivated. I’m just trying to increase the degree of difficulty, which will make a difference only if their efforts are more casual and not directed primarily at me. I’m not unrealistic about the issue here.
And having signed up to these services when they weren’t using social logins (and therefore was not aware of the issue), I’m also putting others on notice as to what is driving this trend, and it most certainly is not their convenience.
Thank you very much for engaging, Yves. Important topic. Let me see if I can try to educate you a bit here.
“We’ve looked into the https: issue and the only reason to do that is to please Google. It’s not going to do bupkis for my security. And it won’t do much for readers either.”
I agree it won’t do bupkis for your security. But both the eminently knowledgeable and trustable Chris Soghoian and I strongly disagree with you on what it will do for your readers’ security.
Here’s one very helpful article, though there are many more. A few crucial cut and paste paragraphs:
In other words, enabling https stops visibility and tracking of an individual merely clicking on a page on your site. It also stops visibility and tracking of an individual posting a comment on your site.
Https stops that.
Https stops that.
Https stops that.
All this is why The Intercept was https default from day one, for example.
I agree with the fact that this is a public website, and https obviously doesn’t protect the content from being publicly read. But in short, by enabling https, no one would be able to track a reader who visits the site, nor track a reader who posts a comment, (unless, of course, they posted under their real name.)
I also agree with most of the rest of your comments on security, especially about how TOR is highly likely a fool’s game. (And even if it’s not, merely using it would instantly mark you for heightened surveillance.)
But I do hope I’ve managed to at least begun to educate you on why https is crucial for a non-mainstream political news site like this one. (Or for pretty much any news / public policy site, for that matter. And to a lesser degree, for pretty much any website.) Thanks for listening.
Except that, once you asked for the DNS records pertaining to nakedcapitalism.com, or the numerous services where the subdomain name is chosen by the customer (archdruidreport.blogspot.com), you stated your intention and lost.
There’s also enough metadata in a well-placed pcap to definitively say “Nobody else posted at 4:19pm yesterday, and you sent a request at just that time to just that server with just enough request payload to have been posting that very lengthy, very well-written exposé…” Dark glasses don’t help when the cops followed your car from your home to the scene of the crime on CCTV. :)
HTTPS does reduce the attack surface for the espioneur, but (as Yves loves to say) complexity is a tax on time, and (as I would say) complexity is just a place to hide loopholes. (DTLS keepalive, ahem…)
There’s also enough metadata in a well-placed pcap to definitively say “Nobody else posted at 4:19pm yesterday, and you sent a request at just that time to just that server with just enough request payload to have been posting that very lengthy, very well-written exposé…”
Entirely correct. An adversary with the resources of Fort Meade could very certainly task a team to collect data from various silos to reconstruct that.
And even more to the point, an adversary with the resources of Fort Meade, if they decide you’re enough of a high value target, can task a team with planting a 0-day on your machine, and simply own you.
But without https, every comment everyone posts (and every page everyone visits), along with an attempt at their identity, is automatically collated and logged. This can be done by both adversaries with the resources of Fort Meade, and adversaries in the private sector with far fewer resources.
“HTTPS does reduce the attack surface for the espioneur”
My point exactly. And it does accomplishes it so well that it’s a reduction in kind, not degree.
It changes the surveilled and logged from everyone, to a fraction the population who are somehow ‘high value targets’ to someone with serious resources.
There’s a reason Snowden, and the folks who’ve read Snowden’s trove, endorse PGP and SSL – aka https. They’re useless if your endpoint has been compromised, or if you’re subject to seriously heroic efforts. But they’re pretty good, in Phil Zimmerman’s sense.
Twitter’s use of https is why they’ve been useful in certain political movements. Readers know they enjoy pretty good privacy in their consumption of political opinion. They’re not being automatically logged as dissidents. And even writers know that, while they’re not invulnerable to government demands, they’re not being automatically logged as dissidents on a mass basis.
“but (as Yves loves to say) complexity is a tax on time”
Oh, but this is so much my point, hunkerdown. Again, my point exactly.
The complexity on Yves part is almost none in technical terms, (highly likely, but not certain), and the monetary component should be relatively trivial.
But it increases the complexity of an adversary to read your pageviews and comments by several orders of magnitude. And that’s what creates the change of kind, not degree. With https, everyones comments are not automatically logged and collated. The web admin has imposed such a massive complexity tax on potential adversaries, that it can’t be automatically done on a mass basis. Even by Fort Meade. (And don’t forget private adversaries.)
Like I say upthread, there’s an argument to be made for all websites to move to https. But the argument for news / politics / policy websites becomes incredibly compelling. Yves isn’t quite behind the curve yet. Pickup has been only mediocre since last June. But it’s a damn good idea, IMHO, especially for a site like this, and I’ve yet to see a decent case against, (other than business concerns like costs for ‘fat pipe’ bandwidth for things like video, or incompatible ad networks.)
I’ve had great success with Feedbin since Google Reader went offline. As I recall, they were the only service that always charged for access at the time (which these days makes them semm more trustworthy to me).
I also use the Reeder app across my iPhone, iPad and Mac which syncs with pretty much all of the services available these days. If you don’t need sync, it also can keep a stand-alone list of your feeds.
Another option is Fever. You will have to host it yourself, but it works pretty well (and also sync with Reeder).
Yves, I understand your pain. Right after I got my first iPhone (3Gs or something), I stumbled into an app-based RSS reader called Pulse. It was awesome, broke down RSS feeds visually, was easy and intuitive to set up, and made browsing a large number of posts very quickly enjoyable. For years I used it happily.
However, Pulse was then acquired by LinkedIn. With the latest update, you cannot view any RSS feeds unless you sign in with either a LinkedIn account or a Google account. Whats more, because it’s attached to LinkedIn, you start to see news stories being pushed by LinkedIn due to other people “in your network” reading those stories, meaning you start to run into the same kind of garbage that seems to populate other social media feeds.
I don’t care about social media garbage. I want to control the news I read, very much like you do. I hope you’re able to find something to mitigate your frustration.
What a nightmare. We are indeed incarcerated the gulag of the Techno-Stasi, a/k/a the Dictatorship of the Capitalist Algorithmiat.
I went through a similar dilemma about using Feedly after Google Reader shut down. I still can’t for the life of me figure out why they nixed it. I know a lot of people who relied on it daily….I had dozens of feeds I would scan there. However, back in July 2013 I didn’t see a way to sign up for Feedly with a regular email address–all I saw at that time were options for social logins, so I never signed up. Now I’ve just pared back my daily website crawl to NC; I can’t be bothered to remember to check much else, which is unfortunate.
RE: “Social Logins” etc.
The comments gave very many sterling suggestions. While not the “millenium”, mine are:
1. Treat “Butt-book” and similar nonsense like posing in your underwear with the shades down;
2. Use Linux, now easy and useful, and especially much more secure; avoid “Microswift” and even Apple like a more contagious form of Ebola;
3. One French Hosting server I’m looking at gives ten email addresses plus generous space for a web site for a few Euros and up; if you are not planning to blow up the “Place de la Concorde” or something similar, they will NOT fink on you to the “Smellers, Snoops and Spies” on the other side of the pond, and could care less if everything is in English or Sanscrit. Your half-remembered high school French should be adequate!
Ditto this for all the websites that require a Facebook login for comments. Or “Disqus” which is basically the same concept of all-seeing-all-collecting monster, just appplied to user comments.
For real! I’ve even happened across pr0n tube sites using Disqus comments. That’s about as misguided as a chat room with one-click bus ticket ordering (VNSFW).
if you’re on a Mac OSX machine, i’ll second the Vienna RSS reader app;
was initially a bit slow – but i’ve got 100+ RSS feeds now, and it’s reasonable.
would also recommend Little Snitch for OSX; takes some getting use to, but watching the n-way fan-out from your system is both fascinating & at times dramatically useful.
in Firefox (or Chromium/Aviator or broken Safari), recommend Ghostery, Disconnect & HTTPS Everywhere plug-ins, and the OSX app Cookie to manage/keep track of such.
and avoid *all* commercial clouds as broken; hopefully Naked Capitalism can now afford/support its own hosted server instantiation with e-mail MTA support, webbie & OwnCloud if you want. keep digital assets always local.
(i run Debian backend servers with Mac’s as the typical user-facing machine.)
best luck!
Posting late on this but still, I’d like to offer my $.02:
Participation in several surveillance-as-business-model platforms such as Twitter, Google, Skype etc. is mandatory for almost everyone these days. The key is to be able to compartmentalize our participation to limit leakage: I need to use Hangouts to conference with my clients, so I accept some feeling up by Larry, Sergei and Eric. But I want to limit that once I’m done using their “free” platform.
This requires the convenient use of what approaches an online legend:
a person with a well-prepared synthetic identity (cover background), called a legend in tradecraft
Things like Chrome’s incognito mode are somewhat of a start, but it has to go much further to be useful: The Qubes Linux variant is a very nice start. It lets you have many “alternate universe” virtual desktops, with reasonably easy yet very controlled/locked-down (lack of) sharing between them. You can even create ephemeral throwaway spinoffs of an environment: Go ahead, use that icky screen-sharing system you need for your conference call, and once done burn the virtual bits down.
Missing piece(s): Network access decoupling
– Tor’s big vulnerability isn’t necessarily the possibility of it being broken; it’s that there’s a trend for surveillance-driven apps/sites to limit or deny access to tor users. Not a surprise given their business model.
This may be a case where irreversible anonymity may actually be a problem because it implies trolling (or worse) which implies lack of/breakdown in trust/willingness to share “innocent” IP addresses.
I keep thinking that cryptocurrency protocols (with or without the -currency part) might be part of a better solution: One where proving a proxied user’s identity is possible, but not without unmasking the act (and possibly identity) of the unmasker themselves.
Oh and if unmasking an alleged troll/bad actor costs a bit of bit-money, that’s even better. You know, in “loosen the coupling to limit the damage” vein.
And that’s why this computer professional (apparently with twice as much experience as Lambert) has no social logins whatsoever.
There is no way to stop the government from spying on you unless you use the TOR browser. Data that is sent over the internet is broken up into packets. Each packet has a header that includes your IP address and the destination of the data IP address. The NSA collects information from each internet provider that includes this header data. If the destination IP address is one that the NSA is interested in, they start looking at everything your IP address is connecting to.
TOR is a browser that makes it impossible to see the destination IP address, since the destination is a TOR server, not the IP address you are really going to. In some cases, the NSA can still detect that you are connecting to a server they are monitoring by measuring the time you connected to TOR and the time TOR connects to the server they are watching. If you often connect to the “bad” server, the NSA might be able to associate the time you connect to TOR to the time TOR connects to the server.
It’s very difficult to remain anonymous; social media is used to collect marketing demographics about you, not for government spying. The NSA is much more pervasive than just using social media to spy.
you mean the “made in u.s. navy” tor?
nope. ethay estbay ayway isway otay eakspay inway odecay.
I switched to running my own RSS aggregator after Google Reader died. Using tt-rss on a RamNode-hosted Debian VM.
@Yves Smith!
You live in Manhattan, don’t you? Why don’t you take a coupe of hours off and contact Eben Moglen at Columbia for help using his guys?
This is who he is: 15 min. Everyone should watch it. http://www.youtube.com/watch?v=gORNmfpD0ak
I use “theoldreader.” I set it up back when google reader died and it recreates the look and feel nearly exactly — down to the 1) nothing needed to install on the computer, and 2) a simple log in and you can access from any computer / device.
It *can* be used through facebook and google+ but it also allows a native oldreader account if that’s what you want. I’ve really appreciated it so far though I suppose it could go bad.
Much belated (I’ve been offline), but potentially helpful if you haven’t found anything else: InoReader and/or The Old Reader. While both offer “social logins,” they’re not required. Both come close to the old Google Reader look and feel, and both support import and export of feeds (so you could do an export as a backup).