Yves here. As Trump is loudly signaling that he might be launching a Presidential bid if Trump-endorsed Republicans do well in the midterms, Tom Ferguson, Jie Chen and Paul Jorgensen have tortured a lot of data to see why some voters are so keen about Hair Furore. Guess what? Once again, it’s the economy, stupid, here the local economy. This paper is a rebuke to Democratic party strategists who dismiss Trump fans as irredeemable bigots. It instead suggests that the Democrats failure to deliver material concrete benefits to voters outside big urban centers has been a boon to Trump. And the Democrats could have prevented that with better, less elite-serving policies.
BTW the Appendix is formidable. If you are at all a data fan, I strongly suggest giving it a good look. You can find it at the end of the original post.
By Thomas Ferguson, Research Director of the Institute for New Economic Thinking, Professor Emeritus, University of Massachusetts, Boston; Jie Chen, University Statistician, University of Massachusetts; and Paul Jorgensen, Associate Professor and Director of Environmental Studies, University of Texas Rio Grande Valley. Originally published at the Institute for New Economic Thinking website
As incitements to genuine fear and trembling, credible invocations of the end of the world are hard to top. So when President Joe Biden mentioned the war in Ukraine and Armageddon in the same breath at a Democratic Party fundraiser, the whole world jumped. Amid a wave of news clips filled with swooning commentary and verbal handwringing, the White House staff rushed to do damage control.1
Yet scary as it was – and is, because what the President discussed is all too real – it is possible to doubt whether allusions to Armageddon fully capture the precarious state of the world today. After all, the classic vision of the Apocalypse in the Book of Revelations starred only Four Horsemen: Pestilence, War, Famine, and Death. The Fearsome Four are all obviously romping over the globe and not just in Ukraine. But nowadays the quartet travels in the company of a veritable thundering herd of other monsters: creatures representing serial climate disaster, inflation, rising interest rates, looming global debt crisis, and broken supply chains, to reel off a few. Not the least of the newcomers is one native to the USA: the prospect that the U.S. midterm elections may confer significant power on a true anti-system party akin to those that terminated the Weimar Republic.
A real understanding of this latest sign of the End Times requires something that even the exceptionally venturesome special House panel investigating January 6th has yet to produce: a detailed analysis of the plotters’ financing and links to the byzantine web of big money that sustains different factions within the Republican Party. (We are very far from considering the GOP as a unitary organism, even if the functional importance of the cleavages is an open question.)
But with the financing of January 6th still shrouded in Stygian darkness, we think a fresh analysis of the voting base of the Trump wing of the Republican Party provides a perfect opportunity to test out twenty-first century machine learning techniques to see if they might shed additional light on the roots of Trump’s appeal. Could they perhaps yield new evidence on the hotly disputed question of how much economic issues matter to Trump voters?
With polls showing that inflation tops the concerns of many voters across virtually all demographic groups, this is perhaps an odd question to pick up on now. But in the last few weeks, many pundits have noticed the relative absence of economic issues in Democratic messaging.2 The party has been emphasizing abortion and Roe vs. Wade. Many academic and literary commentators also continue to short the importance of economic issues in rallying support for Trump, even if we think the evidence is now overwhelming that his secret sauce was precisely a mix of racial and gender appeals with very clear economic ones. As a recent piece in the New York Timesanalyzing Trump voters illustrates, mainstream pundits still treat the subject like cats playing with balls of yarn: they do everything except digest them.3
The research we report here says nothing directly about 2022. But its findings are highly relevant to the election and, we suspect, what comes afterward, even if Congressional elections typically differ drastically from those in which the White House is in play.4 Our idea is straightforward: We search out the factors that drove the Trump vote in counties where he ran ahead of serious Republican congressional contenders in 2020. This is certainly only one of several plausible approaches to sizing up the former President’s leverage within the party, but we think it is more reliable than, for example, tracking districts in which 2022 candidates maintain the pretense that the election was stolen – that tactic likely pays with almost any size contingent of Trump enthusiasts.5
Selecting the most appropriate districts for this exercise requires some care, since we want to exclude ballot artefacts. We eliminated districts in which Republican House candidates obtained 100% of all votes cast. Our reasoning is that if no one, even a minority party candidate, showed on the ballot, the result, to put it politely, may not have reflected an affirmative choice for the House candidate in preference to the President. As long as some minor party candidates qualified for the ballot, though, we counted districts in the sample, even if no Democrat was on the ballot. We had analogous concerns at the other end of the scales. Where no or merely ceremonial Republican congressional candidates ran, the President’s margins over the sacrificial lambs could be equally artificial. We want to exclude both sets of cases, since they likely distort the relative attractions of Trump and Republican House candidates to the President’s mass base. The token cases also probably have little bearing on Trump’s leverage with Congressional Republicans, an issue which, no matter how the 2022 elections come out, is likely to be of burning future interest. We thus exclude races in which Republican congressional candidates failed to attain at least 35% of the vote. We readily acknowledge that no system of controls is perfect and that because county votes can be split up among several congressional districts either honestly or, more likely, due to gerrymandering, it is impossible to eliminate “organizational” artefacts altogether. Figure 1 shows a map displaying how district margins varied across the United States under our criteria.
Figure 1
Difference Trump Vote From Republican House Candidates in Sample
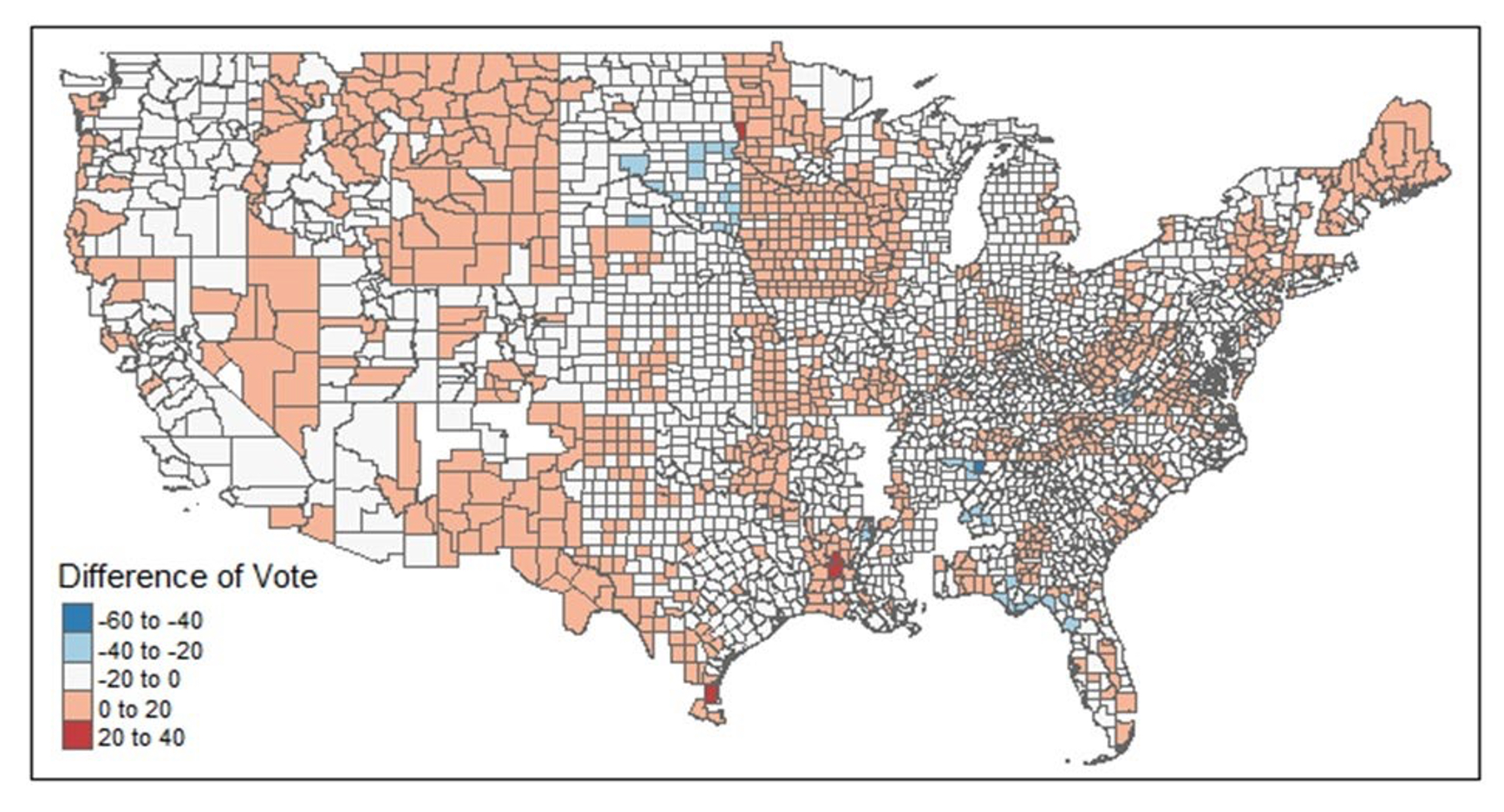
Source: Data From Ferguson, Jorgensen, and Chen, 2021; See Text on exclusions, etc.
This paper builds heavily off our earlier analysis of the 2020 election.6 Like that discussion, it relies not on national poll data, but county-level election returns. That approach has both advantages and disadvantages. The towering advantage is that the importance of place is intrinsic to the method. This permits studies of questions that are difficult or impossible drawing only on data from nationally representative samples of voters or normal exit polls. Those typically have too few cases in any one locality to sort out anything important. Many surveys, indeed, deliberately mask crucial details such as the towns in which voters live to preserve confidentiality.
Especially where Trump is concerned, studies rooted in national polls thus failed to catch many revealing facts. One we often point to is the finding – since paralleled in studies of “populist” movements in other countries — that in 2016 voters who lived in congressional districts with poorly maintained bridges disproportionately favored Trump, holding other factors, including income, constant.7 Or our results for 2020 indicating that in contrast with 2016, counties along the Mexican border voted in favor of the President more heavily than others as did counties with high percentages of Mormons. Perhaps the most striking result of all, however, was the evidence that study produced of the gigantic political business cycle that the Trump team engineered for certain crops in agriculture in its vain effort to win a second term. Such a result – which puts an entirely different face on the celebrated question of how Trump amassed so many votes in 2020 – is virtually impossible to discover unless one looks for it by searching out influences of specific industrial structures on voters (not simply campaign contributions – the focus of much of our other work).8
But a focus on aggregate, place-based voting returns also comes with costs. These need to be acknowledged up front. Some important questions become difficult or impossible to address. Our earlier paper spells out the drawbacks in detail, so our discussion here will be brief. The key point is that all of our findings concern patterns of aggregate data. There is a vast literature on the so-called “ecological fallacy” in statistics warning about what can go wrong in reasoning from wholes to parts in the behavior of particular individuals:
The way patterns at aggregate levels translate into the behavior of individuals is often far more complicated than readily imagined. Often what appears to be a straightforward inference from general results to specific voters is deceptive. Before surveys became ubiquitous, for example, election analysts often drew their evidence about how specific ethnic groups voted from returns in precincts where the group lived en masse. That skipped past questions about whether voters in less concentrated areas might be different or whether other groups in the district might alter their behavior in response and change overall results.9
The corollary is that certain issues of great interest, including how individuals combine issues of race, gender, and the economy in their individual voting decisions are not well approached through aggregate approaches. For that one wants observations on individuals, too, and our earlier paper waved yellow caution flags at many points.10
This paper requires even more forewarnings because it employs a form of machine learning, so-called random forest techniques. The potential pitfalls are numerous and require mention.
First comes a very general issue. Machine learning as a field has developed rapidly, mostly outside the boundaries of traditional statistics. It thrives in computer science departments, giant corporations, companies hoping to be acquired by those, and technically oriented government agencies and labs. Many of its products have a well-deserved reputation for being opaque. The field’s best-known methods – random forests, neural networks, and programs for parsing texts and natural language – are now diffusing rapidly into parts of the natural sciences and medicine, especially genetics, but their use across the social sciences is less common.11 The reception of both random forests and neural networks within economics and political science has been, we think, exceptionally cool. This despite widely trumpeted claims by some economists that resort to “big data” will somehow suffice to solve many traditional problems of economics.
The issues at stake in these debates are too big for this essay to treat in any depth. We will simply state our view that researchers have good reasons to be wary of machine learning. We have never credited claims that big data by itself will solve major problems in economics. But the overriding emphasis that most of the field places on maximizing correct predictions inspires particularly deep misgivings.
We share the conviction, widely voiced by skeptics, that social science should aim at true explanations (“causes” in some quarters) and not simply predictive accuracy in given contexts. Though at first glance explanation and prediction look like Siamese twins, in many real-life situations, the two head in very different directions. Important variables for study may be missing or they co-occur with each other, muddying efforts to pick out which really matters most. Some explanatory variables may also reciprocally interact with each other or the phenomenon under study. These latter problems are especially troublesome; they can resist easy detection and treatment even if recognized.12
Analyzing a unique historical event like an election creates additional problems. In contrast to medical applications, where if results get muddy one can often check how they work on another sample of patients, there is no way to rerun the 2020 election. One can only resample the data. In such circumstances the temptation to rapidly sift the data, publish a list of apparent best predictors, and move on is institutionally very strong, leaving in the dark the true lines of causality.
The 2020 election provided a choice example of a variable that was virtually guaranteed to make confusion: the apparent correlation that many analysts noticed between Trump votes and Covid incidence. That link surely did not arise because Trump voters liked Covid; they were not voting for him for that reason, as simple correlations might suggest. Instead, intense Trump partisans swallowed the President’s claims (including some made at super spreading campaign rallies) that Covid was bogus or just another case of the flu. They accordingly became ill at higher rates, driving up the correlation rate. This is correlation without causation with a vengeance.13
Methods in machine learning for sorting out these and other kinds of data “dependency” are imperfect. The Covid case was not difficult to recognize, though hard to assess quantitatively: In economics papers rushed to embrace a technical fix to tease out the true state of affairs that introduced new errors.14Machine learning elevates this type of problem to a whole new level, since it can sift quickly but coarsely through dozens or even hundreds of variables. Despite some optimistic visions, we do not think there is any foolproof way to identify all troublesome cases. If you suspect reciprocal interaction (endogeneity) between your outcome and the variables you are interested in machine learning methods can help, but we have seen no tools or sensitivity assessments that we would trust to reliably signal them. Nor does any algorithm known to us consistently abstract true general variables out of lower-level cases: if you suspect heavy polluting industries might favor Donald Trump, for example, you will need to order industries according to some criterion and test the set yourself. The machines won’t do it without special promptings.15
We do not find these cautions particularly off-putting. They are not all that different from hazards of normal statistical practice that rarely deter researchers. We very much value the studies of how the results of random forests compare with traditional statistical methods and the efforts to work out the limits of inferences with the new tools. That said, it is impossible to ignore how rapidly machine learning techniques are advancing research across many fields. It is imperative to get on with cautiously testing out the new tools of machines.
Random forest methods, however, take some getting used to, because they differ so much from traditional statistical tools like regression. Firstly, the new technique was developed not to select small sets of best-fitting variables, but to identify as many factors as possible influencing the outcomes of interest. This spaciousness of conception is inevitably somewhat jolting. To analysts steeped in convention, the approach calls up primal fears about the dangers of “overfitting” models with brittle combinations of many variables that doom hopes for generalizations beyond cases at hand. Random forests algorithms typically produce lengthy lists of influential features – sometimes dozens of them. They then flag most as of little importance, testing the patience and credulity of researchers who are used to a traditional emphasis on a handful of key variables.16
A positive reaction to this abundance is that of Athey and Imbrens, who comment that “allowing the data to play a bigger role in the variable selection process appears a clear improvement.”17 In political economy, where pursuit of interaction between political and economic variables is honored mostly in the breach, we think that looking at bigger ensembles of political and economic variables will prove especially beneficial. We predict the practice will sweep away a lot of disciplinary prejudices that have stood in the way of important avenues of inquiry.
A much more substantial stumbling block stems from the variability of results that different random forest programs produce. Right from the beginning, anomalies cropped up in how various algorithms ranked the importance of variables. Depending on the algorithm, results on the same datasets could differ markedly. The discrepancies often went far beyond what could be expected from selection methods defined by long sequences of chance sortings and resamplings.
Results for variables strongly related to each other in a statistical sense were especially treacherous, with the rankings of different features sometimes depending on which variable the algorithm sorted first. Measurement scales of variables also sometimes tilted results.18
These problems precipitated widespread discussion. Techniques for dealing with the problems are evolving rapidly and the situation is certainly much improved. Full discussion of the issues would require far more space than we have. But for this paper, the lesson seemed obvious. We recoil from any notion of trying to settle on a single program yielding a “right” answer in which we might then become heavily invested. A much better idea, though rarely found in the published literature, we think, is to compare the results of several leading programs.
We began with two different, widely used, and well-respected random forest programs. One implements the Boruta Shap algorithm (based, improbably enough, on the famous Shapely index originally developed for analyzing political coalitions), which has won widespread praise as a major improvement in feature selection.19 The second program was one developed explicitly for spatial data like ours, using a different version of the Boruta algorithm.20 Finally, we crosschecked the results from the first two with rankings calculated from a new tool for the sensitivity of random forest results devised by French statisticians. They developed their method to sort out issues of data dependency that had clouded earlier assessments of variable importance.21
County data are, of course, spatial data and the proximity of units to one another can drastically affect statistical estimates, as we have emphasized in previous work on both money and votes. Our past approach to estimating spatial effects through spatial contiguity measures is not well adapted to random forest methods. We thus turned to a method used by geographers that translates distance measures into sets of Moran eigenvectors that are added to the data set as predictive variables.22 The technical details and references are in the Appendix.
We have long been impatient with election analyses that fixate on a handful of demographic variables and a few traditional economic indicators such as median income. That was why our 2020 paper looked so long at potential influences on voters of industrial sectors that bulked large in their districts. In this paper we again tried to take full advantage of the large number of counties to analyze a much bigger set of industries and farm sectors, along with the usual ethnic, racial and religious indicators beloved in mainstream social science and journalism. Our results were interesting indeed. All three programs produced the “hockey stick” list of measures of variable importance typical of random forest studies. As Figure 2 illustrates, the variables (“factors”) can be ordered in successive importance from highest to lowest along the horizontal axis. Each factor’s height indicates its ranking, so that the major factors all cluster on the left side and the myriads of less important factors tail off to the right. Typically, twenty or so factors dominate the list, making it attractive to concentrate on them.
Figure 2
Top 20 Variables Arrayed by Importance, SobolMDA
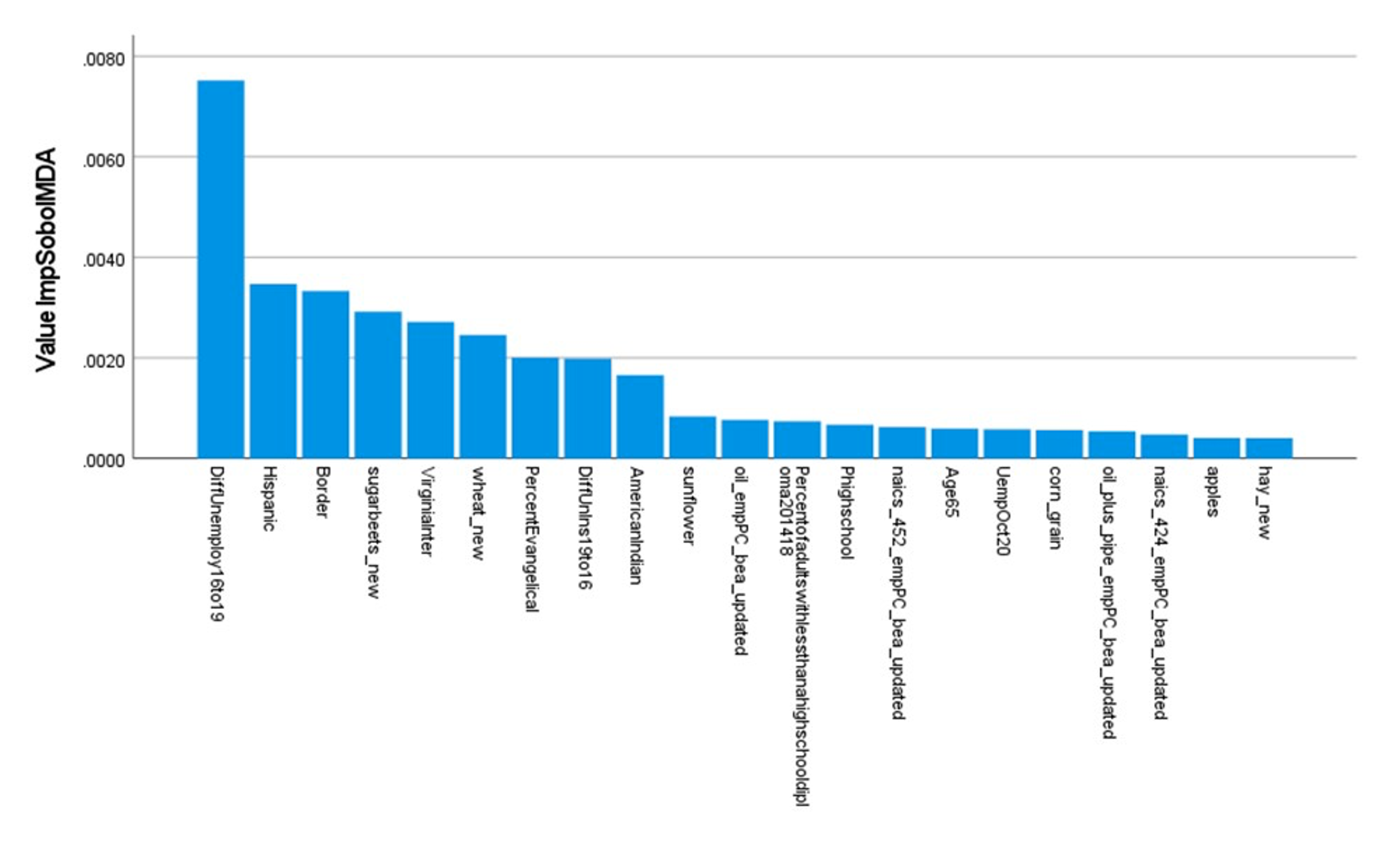
Strikingly, all three programs selected an economic variable identified in our 2020 study as most important for predicting Trump’s vote margin relative to Republican congressional candidates: the county change in unemployment rates between 2016 and 2019. The more unemployment fell, the greater the increase in Trump voting. But the programs disagreed on rankings for other variables, though many were close to each other, and it is unreasonable to expect that programs that work by repeated samples will agree perfectly.
But the differences were hardly negligible, either. We thus proceeded to the next phase of our analysis. We pooled the top twenty variables that each program ranked as most important and considered the whole set in more detail. Appendix Table 1 lists them.
We evaluated the variables using our familiar technique of spatial regressions.23 Once again, for details and references, see our Appendix below as well as our earlier paper. It is only sensible to acknowledge that proceeding in this way comes with a built-in bias toward methodological conservatism. Champions of random forests trumpet the ease with which the method accommodates non-linear relationships of all kinds. Checking results of random forests against the output of spatial regressions is hazardous, because only some forms of non-linearity are readily tested with traditional tools. More complicated combinations resist easy identification.
Researchers need to come to terms with this. We have tried to make due allowance for the point.
Conclusion: The Trump Base and the Persisting Importance of Economic Issues
We are the first to agree that there are plenty of possible reasons to question our results. Our discussion has flagged many points where the inquiry could go off the rails and we will not repeat the litany of cautions again. It should also be obvious from our Appendix, which sets out the full list of variables that we analyzed in the last stage of our inquiry and selected output from the random forest programs we relied on, that one could write a much longer paper about the results. We are planning to do precisely this, but we also think that many issues concerning both methods and results could benefit from further inquiry. This includes the reasons why some variables that often figure in discussions of election results did not make the grade, such as median income, though that particular case is perhaps not perplexing. The same holds for many less familiar variables that appear in Appendix Table 1’s list of the variables selected for further study.
Yet we think our research to date yields a basic finding that is clear and reliable, not just in its own terms, but because it fits with results of other papers. And it can be stated very concisely, by simply moving through the variables in our final model. Here we discuss these non-technically; our Appendix Table 2 sets out and explains in more detail the variables that appear to matter most for catapulting the vote for Trump well over those of Republican House candidates in some districts.
Certain “demographic” variables indeed show as important: Trump’s margin over Republican House candidates ran higher in districts with more Catholics, Hispanics, in districts with more voters whose education stopped with high school, and in counties on the border with Mexico. Counties with higher proportions of older voters also showed more support for Trump than for Republican congressional candidates. This doesn’t mean that older voters preferred Trump to Biden in general; this gap may well reflect what older voters thought of the much more strident demands by many Republican congressional candidates for fiscal responsibility and even their criticisms of Social Security.24
Our results for Covid’s effects parallel those of our earlier paper for the presidential election, but with a twist. The earlier paper indicated that Covid’s effects varied substantially depending on the number of Trump partisans in districts. Where his support was strong, more people tended to trust the President’s assurances that Covid was really nothing special. By contrast in counties where Trump received less than 40% of the vote, skepticism about the President’s assurances ran much deeper. Higher rates of Covid diminished his vote to a much greater degree.
Trump’s advantage compared to Republican candidates showed analogous switches. High rates of Covid lowered Trump’s margin against Republican congressional candidates everywhere, but the extent to which they did varied markedly. In the high Biden counties, where Republican congressional candidates were less popular to begin with and a vote for the President ran against majority sentiment, the President started out with a larger advantage among stalwarts who stayed with him. But that advantage melted at a higher rate than elsewhere as Covid rates rose.25 Most commentary since the election takes it for granted that Republican voters were relatively unmoved by Covid, rather than simply preferring Trump to Biden in the head-to-head match. Our results suggest that neglect of evidence-based health analyses can be costly even inside the Republican party for the person who is taken to be primarily responsible.
Two variables might be counted as “political.” Trump’s combative responses to mass protests are well known. This perhaps worked to gain him a few votes by comparison with other Republican House candidates, though among all voters it cost him in the general election against Biden.26 The question of whether differences in the expansion of health insurance cost Republicans votes in the presidential election has been debated, unlike the case of 2018, which seems clearer. Our tentative finding is that here, again, the fiscal conservatism typically displayed by Republican congressional candidates did not help them. Trump, by contrast, often dodged responsibility for his party’s and his administration’s efforts to retard healthcare expansion and appears to have benefited from those deceptive moves.27
The rest of the variables are all economic. The agricultural and industrial sectors listed in the table by their numbers in the North American Industrial Classification system are relatively straightforward, though why certain of the industrial sectors turn out to be important is a subject too complicated to discuss here.28 The novelty of the whole line of inquiry calls for extended reflection. This is not political money; in some cases votes might shift for reasons no social scientists have thus far caught, simply because they have hardly looked. Most studies of the mass political effects of specific industries concentrate almost exclusively on cases in which labor was already or was becoming heavily organized. At least up till now, the U.S. is quite far from this situation, though in the past periods of high inflation have eventually led to major labor turbulence.
The remaining economic variables are easier to interpret. As discussed, our earlier paper showed that in counties where rates of unemployment dropped the most, Trump gained votes against Biden. This paper indicates he also gained votes against Republican congressmen and women in those counties. The finding in our earlier paper that in counties where unemployment was especially high in 2020 Trump’s association with economic growth benefited him also holds up here. It advantaged him within his own party.
These results, we think, confirm that Trump’s appeal to his base rests importantly on economic issues, especially economic growth. We repeat that we are not claiming that the economic issues are all that matter: anyone, now, should be able to see how Trump routinely exploits racial and ethnic themes. But the economic appeal is important and not reducible to the others.
As we finished work on this paper, the New York Timespublished a piece highlighting racial themes that it believed defined Trump’s basic appeal. The article’s test for assessing Trump’s influence was whether Republican members of the House voted to support the challenge to the Electoral College vote on January 6th, 2022. The article was careful: it noted that these districts also showed lower median incomes and lower rates of educational attainment. But it focused on racial prejudice as the key to Trump’s attraction, citing its finding that districts whose representatives voted to support the challenge tended to be districts where the percentage of (Non-Hispanic) whites in the population had declined the most over three decades.29
The Times study compared Congressional districts, not counties, and covered the whole country, not simply districts where Republican candidates mounted serious challenges to Democrats. We readily salute the Times for making the inquiry and find the result very interesting. But our study raises doubts about the uniquely heavy emphasis it places on race.
We are using county data. While county borders change much less over time than congressional districts, some do alter over a generation. But mutations since 2010 are truly minute. Given what is known about how diversity has generally increased across the United States counties since 2010, it seems obvious that if white flight is actually driving the process, then it should show in the time period in which Trump burst on the political scene and won the Presidency. So we tested county rates of change in the white, non-Hispanic percentages of county population between 2010 and 2019 to see if they changed our results. That variable failed to have significance; the other variables continued to work well.
We repeat, again, that this does not mean that racial appeals are not basic to Trump’s appeal to parts of his base. But the result should add plausibility to our claim that economic issues are a separate and very important part of his appeal. As inflation tears into the real incomes of most of the population, this lesson perhaps needs to be absorbed as the driverless car of world history careens to and fro. Otherwise, as the age of electric cars dawns, at least four or more horses and their dreadful riders might someday soon materialize in the sky over Washington, D.C.
______
Please see original post for the Appendix and References
The authors are very grateful to Blas Benito and Clément Bénard for very helpful and timely responses to questions.
Thanks also to Charles Delahunt and Shawn McGuire for early encouragement and to the Institute for New Economic Thinking for support that made it possible for us to run two machines at once. Thanks also to Pia Malaney for comments on the manuscript and Zihan Li and James Hershman for other helpful advice
1 See, e.g., (CNBC, 2022).
2 (Gaspard, Greenberg, Lake, & Lux, 2022) among many sources.
3 For the scholarly discussion, see the references in (Ferguson, Jorgensen, & Chen, 2021) and (Ferguson, Page, Rothschild, Chang, & Chen, 2020). The Times piece is (Keller & Kirkpatrick, 2022).
4 2018’s extraordinary turnout, reminiscent of a presidential election, suggests that something may be changing in the political system.
5 By including Republican candidates who have little or no chance of winning, it may also send investigators down a false trail if the real question is Trump’s position vis a vis Republican congressmen and women.
6 (Ferguson et al., 2021).
7 (Ferguson et al., 2020) for 2016; for an Italian case cf. (Cavallaro, 2021).
8 We treat agricultural sectors as special cases of a broad “industrial” structure, as our paper explained. 9 (Ferguson et al., 2021). The point applies, too, discussions of Trump’s margins compared to other Republican candidates. Party line voting should not be assumed regardless of all the talk of increased partisanship.
10 We caution about claims that individuals vote on only one or two issues. They don’t, and nothing in this paper assumes they do. But when a broad issue like economic decline affects large numbers of people, the pros and cons of candidates and parties as voters perceive them will change broadly. See the discussion in (Ferguson, 1995), esp.
the Appendix, but also the empirical evidence of voters’ misgivings about Trump in (Ferguson et al., 2020).
11 Methods for analyzing natural language texts are becoming much more common, even if many problems remain.
12 The literature is copious; see, e.g., (Athey & Imbrens, 2019); (Mullainathan & Spiess, 2017). Specifically on instrumental variables, where a possible use for them is recognized see, e.g., (Angrist & Frandsen, 2019), which offers many cautions. On causal explanations, see the succinct statement of problems in (Shiffrin, 2016).
13 See the discussion in (Ferguson et al., 2021); technically the phenomenon is an example of “rationalization” where some voters adopt the issue stance of a candidate they trust.
14 Various papers sought to solve the problem by means of an instrumental variable. They chose meat packing as the variable. (Ferguson et al., 2021) explains why the use of that introduces new errors. The solution we advanced is not perfect either, but it does not stray as far from reality as other solutions.
15 Cf. (Shiffrin, 2016): comments that “However, there are enormous difficulties facing researchers trying to draw causal inference from or about some pattern found in Big Data: there are almost always a large number of additional and mostly uncontrolled confounders and covariates with correlations among them, and between them and the identified variables. This is particularly the case given that most Big Data are formed as a nonrandom sample taken from the infinitely complex real world: pretty much everything in the real world interacts with everything else, to at least some degree.” One is reminded of Hegel’s famous dismissal of Schelling’s Absolute as a night in which all cows are black.
16 The danger of “overfitting” models with too many variables is heavily stressed in traditional statistics. See (Athey & Imbrens, 2019); a lucid discussion of the contrasting approaches is (Bénard, Da Veiga, & Scornet, 2022). See also the seminal early paper by (Breiman, 2001).
17 (Athey & Imbrens, 2019); the quotation continues: “even if the assumption that the underlying process is at least approximately sparse is still a strong one, and even if inference in the presence of data-dependent model selection can be challenging.”
18 The literature is very large. (Strobl, Boulesteix, Kneib, Augustin, & Zeileis, 2008) was a particularly helpful early critique. See also (Debeer & Strobl, 2020).
19 See, e.g., (Bénard et al., 2022) or (Kou, 2019).
20 (Benito, 2021).
21 (Bénard et al., 2022).
22 (Dray, Legendre, & Peres-Neto, 2006); (Griffth & Peres-Neto, 2006); (Hengl, Nussbaum, Wright, Heuvelink, & Gräler, 2018). An interesting application is (Saha, Basu, & Datta, 2021).
23 The spatial regressions followed the pattern of our 2020 paper: These use spatial contiguity as the basis for the spatial matrix and included a set of fixed effects variables for states.
24 Our Appendix Table includes a term for a few counties in Virginia and indicates these were less friendly territory for Trump. They are singled out simply because data peculiarities specific to some federal tabulations for that state required us to interpolate a few entries. None of the details matter for this paper, but we left the term in for completeness.
25 The use of the interaction in preference to a more usual instrumental variable for assessing Covid’s effect is explained in (Ferguson et al., 2021), section 3. The positive sign for the High Biden districts almost surely means that the voters who did cast votes for Trump liked him better than Republican House candidates running in their district, which is hardly a surprise.
26 (Ferguson et al., 2021).
27 We take it as a given that the Trump administration in fact strongly opposed extending health insurance, but that Trump usually tried to duck responsibility for the decisions. In the 2016 he clearly dodged such questions. Cf. (Ferguson et al., 2020). Republican congressmen and women, by contrast, we believe were much clearer about their views.
28 Some of the agricultural sectors are fairly obvious; Trump’s administration killed planned reports on the dangers of some crops, for example. More another time. It is worth noting that heterogeneity within some industrial sectors can be important.
29 (Keller & Kirkpatrick, 2022).
30 (Ferguson et al., 2021).
31 (Eckert, Fort, Schott, & Yang, 2021).
32 (Benito, 2021).
33 For Ranger, see (Wright & Ziegler, 2017); for the distance matrix approach cf. (Dray et al., 2006) and (Hengl et al., 2018).
34 (Bénard et al., 2022).
35 (Anselin, 2002); (LeSage & Pace, 2009).


Hmmmmm…..good luck getting the idealogues in the Dem Party leadership to consider anything other than emotive issues….I can’t believe these morons could do a worse job than a game show host but here we are…
The emotive issues and culture warring allows the democratic leadership, and indeed the entire political class, to avoid addressing the underlying economic issues and their needed reform. Endless tribalism is a means.
Its unfortunate that this study only went to 2010. If they looked, the real roots of Trump are probably found in 2008 when people voted for Candidate Obama and got President Obama instead, who proceeded to bail out the banks and insurance companies and did not prosecute a soul. In addition to the 2008 Financial Crisis, the opioid epidemic fueled by Big Pharma pushing oxycontin, and the ensuing rain of overdose deaths, combined with a particular kind of PMC tone-deafness for the suffering of others, led to 2016. No one really knows what will happen today, but if the Democrats get stomped, they’ll just double down and maybe gin up the NGO-funded electoral-year riot industry a year early to show that the manufacturers of astroturfed street violence are really mad. Color revolution starts at home!
Ferguson did do an earlier, narrower county level study that sort of confirms your point. He looked at why Republican Scott Brown won Ted Kennedy’s seat in a 2010 Mass special election, again using a county-level analysis. The share of vote that went to Brown correlated strongly with the level of foreclosures by county. This site was early and often to criticize Obama’s failure to do anything to stop largely preventable foreclosures. Many borrowers had missed only a payment or two due to income interruptions, or would still produce a lower loss with a modification than a foreclosure. In the old days of bank-owned mortgages, the bank would have cut a deal, but not with securitized mortgages, where bank servicers had a highly streamlined process for foreclosing, but not for doing mods, which would amount to a more labor-intensive new mortgage underwriting. I could go on at great length about the Obama Administration’s criminal negligence, so let me stop here.
Interesting – thanks for pointing out the effects of mechanizing/computerising a previously human-intervened process, that of managing mortgages in arrears/default. To me, a basic of systems design is to have a human at critical decision nodes empowered to make decisions, subject to oversight/audit. By making mortgage decisions an algorithmic function, and reducing the humans involved to servants of that algorithm, very bad decisions result.
I think this problem has application in several aspects of our social structures. It’s a strange form of totalitarianism where the machine makes the decisions that are enforced by its human servants.
It is not a matter of mechanizing but standardizing.There was still a lot of human activity, like the famed robosigning.
And the pathetic thing is: had bailout funds gone to and thru the borrowers to make their payments, the banks still would have been made whole. But no, they had to make the little people suffer. It’s enough to make one believe in evil intent.
There are too many examples of policies that directly result in the suffering of Americans for me to believe there is a lack of intent.
This seems logical except it doesn’t explain 2012.
Bill Clinton: it’s the economy, education and the environment.
Biden: strike three call!
Americans want an economic Huey Long (left of center, see FDR) who is centrist-agnostic to right-leaning on cultural war issues (Trump was the closest thing in 2016).
And the voters are wising up that both the GOP and Dem elites (McConnell and Pelosi) disdain their own bases.
See this chart from https://www.voterstudygroup.org/publication/political-divisions-in-2016-and-beyond
https://www.voterstudygroup.org/assets/i/reports/Graphs-Charts/1101/figure2_drutman_0f0a8d3f454ee77070d5a9761c8258a5.png
I won’t bother to do a count but the number of times the word “Trump” appears in the above may be the secret to Trump’s rise. The fact that Trump scares the crap out of the elites is likely his true appeal to the wearers of Viking hats. Meanwhile a study of history rather than statistics could reveal that comparisons to what happened in the last century are superficial. I realize the purpose of the above is to debunk the Trumpism = racism meme but I don’t think you need a study for that. It’s all we’ve been talking about since 2016. If the establishment is just now finally getting the message then that’s on them.
Ever since “it’s the economy stupid” in 1992 it’s been obvious that the American public are deeply disillusioned with the direction of the country so “Trumpism” is by no means a recent phenomenon. Trump was simply their way of trying to shake things up after his recent predecessors failed to deliver. That he did the politician thing of sucking up to his donors instead is merely more evidence that he is a weak and vain figure and not the bogeymen that many think. It’s the system that’s broken and whatever happens in 2024 fixing it is still unlikely to be on the ballot. Liberal organizations like Common Cause used to understand this but now the left uses Trump as the great distraction. Personally I think Biden is a lot scarier than the American public that we out here in flyover live among. If there is a fascist undercurrent–and there is– it’s more likely among the upper class who have the most to lose from reform. That’s your historical analogy.